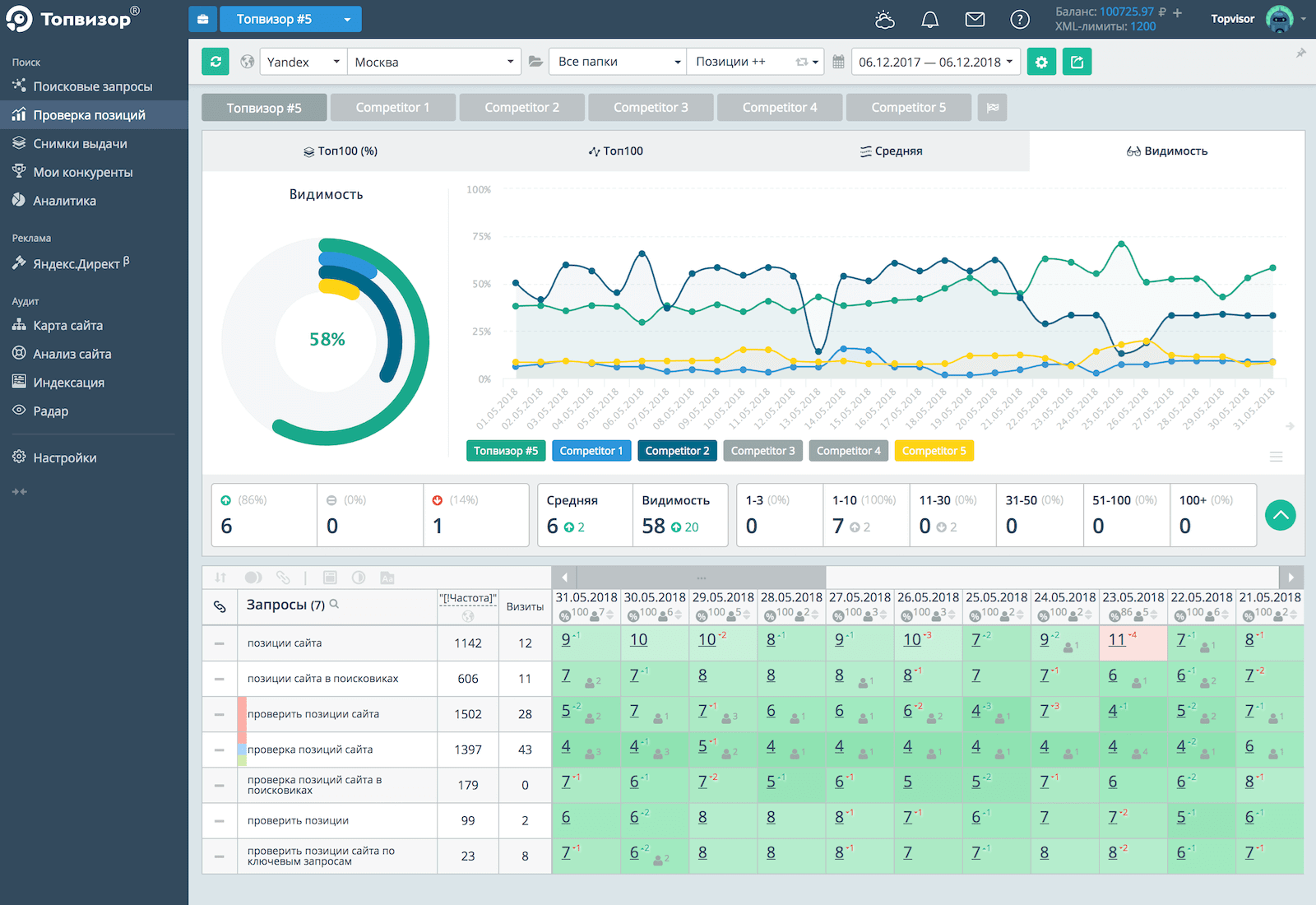
Есть. Называется int. Вам надо хранить количество десятитысячных в числе. Иными словами, вы вместо x храните в int x*10000. При выводе делите на 10000 (и установите выводить 4 знака).
Такие числа можно просто складывать и вычитать. При умножении надо будет результат поделить нацело на 10000 (или округлить к ближайшему, делящемуся на 10000 и потом отбросить 4 нуля). При делении - наоборот. Надо сначала домножить числитель на 10000, а потом поделить нацело на знаменатель (возможно стоит подумать об округлении к ближайшему целому).
Upd: И вообще, раз уж разговор о C++, то можно реализовать свой класс. Там можно даже отдельно хранить целую часть и 4 знака после запятой. Если вам встроенной точности int/int64_t не хватает. Все математические операции можно переопределить и работать, как со встроенным типом. Вообще, по-умному, это называется fixed point numbers.