Вопрос 1. Два конвейера позволяют только сократить накладные расходы на context switch. Параллелизм это не увеличивает, так как вычислительное ядро по-прежнему одно.
Вопрос 2. Верно. Разделите понятия процесс и поток. Думайте о процессе как о контейнере для потоков, а не как об активной сущности, которая исполняет код. В каждом процессе есть как минимум 1 поток. Все без исключения программы стартуют как однопоточный процесс, который имеет возможность превратиться в многопоточный, заспавнив ещё потоков. Ну и, соответственно, ОС шедулит потоки, а не процессы.
Вопрос 3. Нет. Процессор сам подгружает инструкции из кеша/основной памяти. Потоки не совершают никаких дополнительных действий для этого. Всё происходит прозрачно для потока.
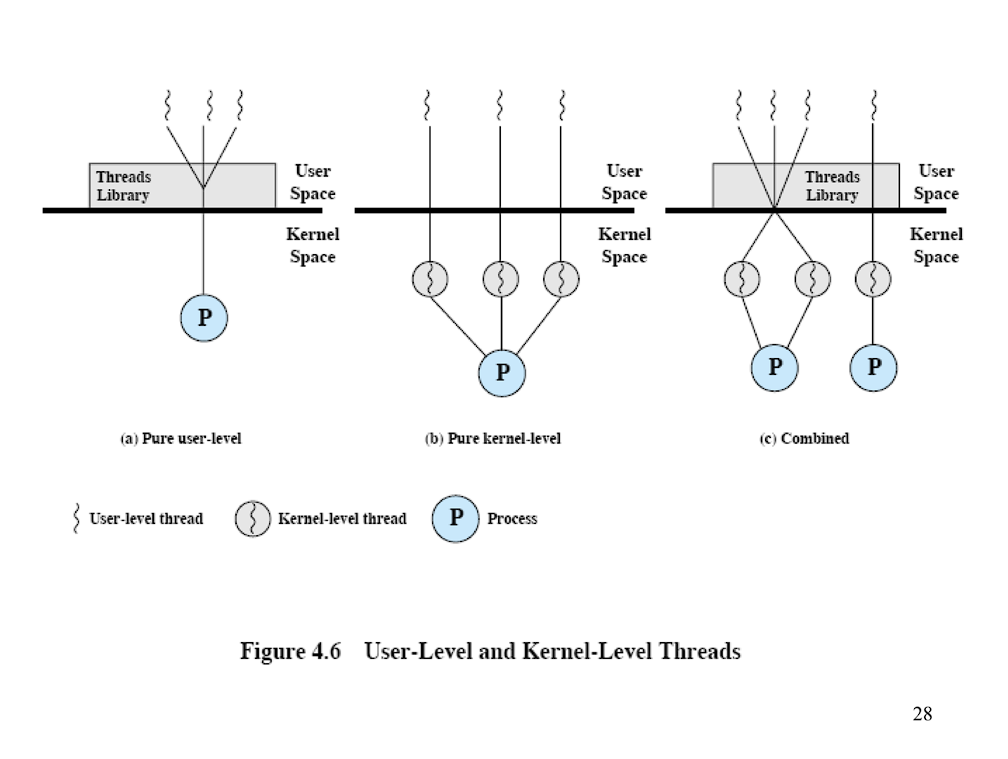
Вопрос 4. Kernelspace и userspace потоки отличаются только тем, в каких
кольцах они исполняются. Kernel потоки исполняются в привилегированных кольцах, а user потоки в непривилегированных. Во всём остальном эти потоки ничем друг от друга не отличаются. Кольца ограничивают набор процессорных инструкций и системных вызовов, которые поток может использовать. Например, чтение файла с диска - это привилегированная операция (так как требует прямого доступа к девайсу), поэтому когда обычный userspace поток хочет прочитать файл, ОС приостанавливает userspace поток и передаёт управление kernelspace потоку, у которого достаточно привилегий на выполнение данной операции.
Кооперативную многозадачность можно сделать и самому. Концепция называется
green threads. В языках программирования встречается уже готовая реализация грин тредов, только называется иначе: корутины (python), горутины (go), виртуальные потоки (java). Все они делают одно и то же - реализуют кооперативную многозадачность в userspace. При большом желании можно написать и свою реализацию грин тредов без использования уже готовых языковых инструментов. Хотя практического смысла в этом мало (кроме нарабатывания опыта).
Вопрос 5. Думаю, ответ на этот вопрос очевиден из ответа на предыдущий.
И всё же под "kernel" обычно подразумевают ядро ОС, а не ядро процессора (которое называют core, а не kernel). Единственный способ запустить поток в kernelspace - написать модуль/драйвер ядра. Обычные программы так не могут.
Финальный вопрос. Правильно понимаете. Вот только "пошаговая стратегия" - это про многозадачность, а не про параллелизм. Процессор с одним ядром многозадачным быть может. Параллельным - нет.




 Средний
Средний