Нет, запрос сделан неправильно! Он, дополнительно к тому, что требуется, выберет еще и пользователей, которые
написали комментарий, даже если их собственные статьи никто не комментировал... не говоря уже о том, что если нет явной необходимости аггрегирования полей в группе, то использование GROUP BY там, где можно обойтись DISTINCT - дорогое удовольствие (почему - объясню дальше, а пока, просто для сравнения, его план и "стоимость"):
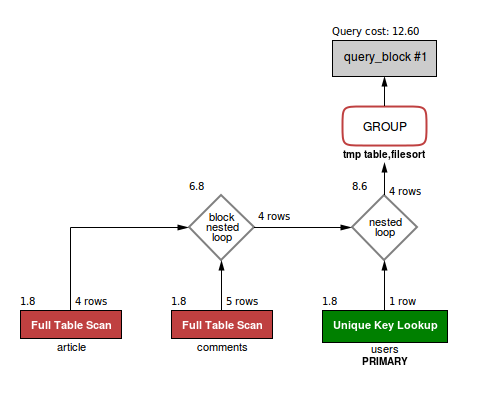
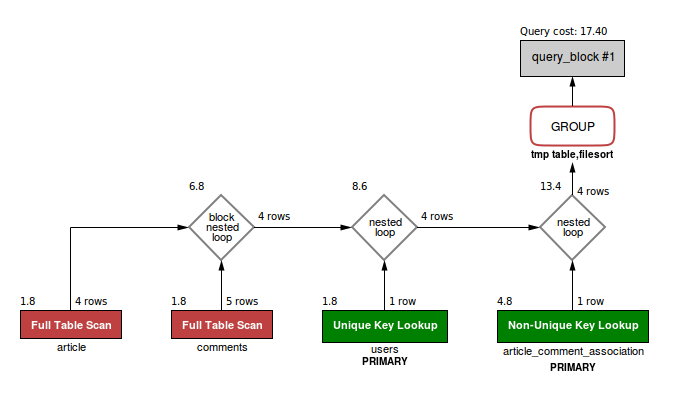
Чтобы просто получить нужный результат, его, конечно, можно тупо дополнить еще одним JOIN с
article_comment_association, но это все еще очень плохо: во-первых, JOIN с таблицей комментариев там просто лишний, во-вторых, GROUP BY - все то же разбазаривание ресурсов:
Вот, для сравнения, стоимость DISTINCT vs. GROUP BY:
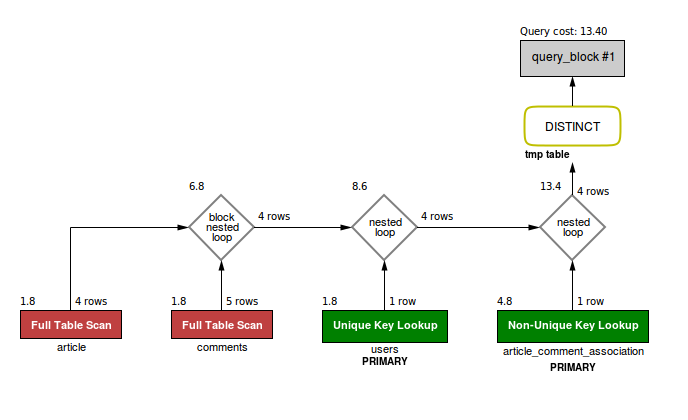
(Все эти неправильные варианты приводить не буду, чтоб их случайно не скопипейстили в систему управления ядерным реактором!)
В этом смысле вариант, предложеный
Rsa97 , уже лучше, т.к. дает правильный результат.
SELECT name FROM users
WHERE id IN (
SELECT user_id FROM article
WHERE id IN (
SELECT article_id FROM article_comment_association
)
);
Однако, использование subquery в таком порядке, действительно, не позволяет использовать distinct:
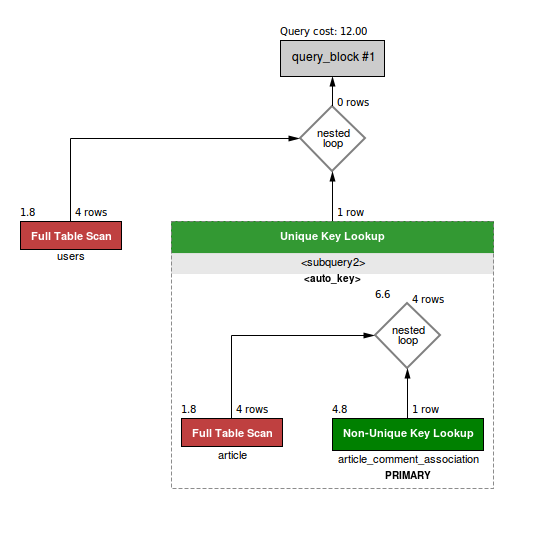
Фишка в том, что subquery, как правило, создают временную таблицу, обычно, в памяти, но если ее мало, то и на диске. Так что, если есть возможность заменить их на JOIN (а она есть почти всегда!), это нужно делать, не стесняясь.
А вот феншуйная (она же - правильная, легко читаемая, очевидная и эффективная) версия запроса:
SELECT distinct users.name from users
INNER JOIN article ON (article.user_id = users.id)
INNER JOIN article_comment_association ON (article.id = article_comment_association.article_id)
... и ее план:
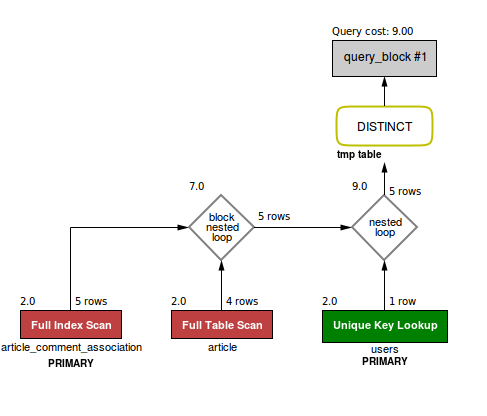
Мораль истории: в реляционной базе данных самый прямой путь к нужному результату, как правило, оказывается наиболее эффективным. Как общее правило - начинать нужно с самого большого множества записей, исключая за раз как можно больше ненужного, и давая оптимизатору использовать индексы.










