

.env.example с примерами настроек..env файлы, во-первых, содержат критические данные (логины пароли от дб как минимум), во-вторых, зависят от окружения и могут отличаться на проде , деве и у каждого программиста в команде локально. create table products (
id serial primary key,
name text not null
);
create table products_attributes (
id serial primary key,
attribute_id int not null,
product_id int not null references products (id),
value double precision
);
-- 10 млн продуктов
insert into products (name)
select 'p' || n from generate_series(1, 10000000) n;
-- в среднем по 10 аттрибутов на продукт
-- всего 20 разных аттрибутов
-- значения - случайные из 1-1000
insert into products_attributes(attribute_id, product_id, value)
select a,
p.id,
trunc(random() * 1000)
from products p, generate_series(1, 20) a
where random() < 0.5;
create index ix_attr_attribute_id on products_attributes(attribute_id);
create index ix_attr_product_id on products_attributes(product_id);
create unique index uk_attr_attr_product on products_attributes(product_id, attribute_id);
create index ix_attr_value on products_attributes(value);
-- немного статистики
select attribute_id, count(*) from products_attributes group by 1 order by 1;
attribute_id | count
--------------+---------
1 | 5001345
2 | 5001937
3 | 4998754
4 | 4998706
5 | 4999357
6 | 5004465
7 | 4999215
...
select product_id, count(*) from products_attributes group by 1 order by 2 desc limit 20;
product_id | count
------------+-------
4769292 | 20
5366802 | 20
7241348 | 20
3019891 | 20
7789046 | 20
1688646 | 19
1585970 | 19
...
SELECT count(*) FROM products_attributes WHERE attribute_id = 1 AND value BETWEEN 1 AND 400;
count
---------
1999212
(1 row)
SELECT count(*) FROM products_attributes WHERE attribute_id = 2 AND value BETWEEN 1 AND 400;
count
---------
1999385
(1 row)
SELECT count(*) FROM products_attributes WHERE attribute_id = 3 AND value BETWEEN 20 AND 30;
count
-------
55318
(1 row)explain analyze
select * from products
where id in (
select product_id from products_attributes
where attribute_id = 1 AND value BETWEEN 1 AND 400
)
and id in (
select product_id from products_attributes
where attribute_id = 2 AND value BETWEEN 1 AND 400
)
and id in (
select product_id from products_attributes
where attribute_id = 3 AND value BETWEEN 20 AND 30
);QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=164603.86..347381.12 rows=2047 width=12) (actual time=680.688..3753.927 rows=2189 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Nested Loop (cost=163603.86..346176.42 rows=853 width=12) (actual time=652.714..3713.617 rows=730 loops=3)
-> Nested Loop (cost=163603.43..341334.66 rows=762 width=12) (actual time=652.439..3294.369 rows=730 loops=3)
-> Parallel Hash Join (cost=163602.86..313081.39 rows=4167 width=8) (actual time=649.437..1742.210 rows=3689 loops=3)
Hash Cond: (products_attributes_1.product_id = products_attributes_2.product_id)
-> Parallel Index Scan using ix_attr_attribute_id on products_attributes products_attributes_1 (cost=0.57..147444.27 rows=775173 width=4) (actual time=0.577..880.079 rows=666462 loops=3)
Index Cond: (attribute_id = 2)
Filter: ((value >= '1'::double precision) AND (value <= '400'::double precision))
Rows Removed by Filter: 1000851
-> Parallel Hash (cost=163306.17..163306.17 rows=23690 width=4) (actual time=647.483..647.483 rows=18439 loops=3)
Buckets: 65536 Batches: 1 Memory Usage: 2752kB
-> Parallel Index Scan using ix_attr_attribute_id on products_attributes products_attributes_2 (cost=0.57..163306.17 rows=23690 width=4) (actual time=18.296..639.541 rows=18439 loops=3)
Index Cond: (attribute_id = 3)
Filter: ((value >= '20'::double precision) AND (value <= '30'::double precision))
Rows Removed by Filter: 1647812
-> Index Scan using uk_attr_attr_product on products_attributes (cost=0.57..6.78 rows=1 width=4) (actual time=0.420..0.420 rows=0 loops=11066)
Index Cond: ((product_id = products_attributes_1.product_id) AND (attribute_id = 1))
Filter: ((value >= '1'::double precision) AND (value <= '400'::double precision))
Rows Removed by Filter: 0
-> Index Scan using products_pkey on products (cost=0.43..6.35 rows=1 width=12) (actual time=0.572..0.572 rows=1 loops=2189)
Index Cond: (id = products_attributes.product_id)
Planning Time: 4.481 ms
JIT:
Functions: 93
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 14.220 ms, Inlining 0.000 ms, Optimization 2.852 ms, Emission 50.889 ms, Total 67.961 ms
Execution Time: 3762.035 ms
(29 rows)explain analyze
select * from products
where id in (
select product_id from products_attributes
where attribute_id = 1 AND value BETWEEN 1 AND 400
)
and id in (
select product_id from products_attributes
where attribute_id = 2 AND value BETWEEN 1 AND 400
)
and id in (
select product_id from products_attributes
where attribute_id = 3 AND value BETWEEN 20 AND 30
) limit 20;QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2.14..7292.14 rows=20 width=12) (actual time=3.743..47.724 rows=20 loops=1)
-> Nested Loop (cost=2.14..746133.39 rows=2047 width=12) (actual time=3.741..47.714 rows=20 loops=1)
-> Nested Loop (cost=1.70..734511.89 rows=1829 width=12) (actual time=3.313..44.710 rows=20 loops=1)
-> Nested Loop (cost=1.14..666709.45 rows=10000 width=8) (actual time=2.377..42.276 rows=95 loops=1)
-> Index Scan using ix_attr_attribute_id on products_attributes products_attributes_2 (cost=0.57..209246.27 rows=56856 width=4) (actual time=1.250..14.969 rows=511 loops=1)
Index Cond: (attribute_id = 3)
Filter: ((value >= '20'::double precision) AND (value <= '30'::double precision))
Rows Removed by Filter: 46859
-> Index Scan using uk_attr_attr_product on products_attributes products_attributes_1 (cost=0.57..8.05 rows=1 width=4) (actual time=0.053..0.053 rows=0 loops=511)
Index Cond: ((product_id = products_attributes_2.product_id) AND (attribute_id = 2))
Filter: ((value >= '1'::double precision) AND (value <= '400'::double precision))
Rows Removed by Filter: 0
-> Index Scan using uk_attr_attr_product on products_attributes (cost=0.57..6.78 rows=1 width=4) (actual time=0.025..0.025 rows=0 loops=95)
Index Cond: ((product_id = products_attributes_1.product_id) AND (attribute_id = 1))
Filter: ((value >= '1'::double precision) AND (value <= '400'::double precision))
Rows Removed by Filter: 0
-> Index Scan using products_pkey on products (cost=0.43..6.35 rows=1 width=12) (actual time=0.149..0.149 rows=1 loops=20)
Index Cond: (id = products_attributes.product_id)
Planning Time: 9.959 ms
Execution Time: 47.796 ms
(20 rows)
Подскажите каким образом можно вырезать светлую прямоугольную область?
import cv2
import numpy as np
img = cv2.imread("C:\\Users\\ramas\\Documents\\321.png")
def process(img):
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(img_gray, 128, 255, cv2.THRESH_BINARY)
img_blur = cv2.GaussianBlur(thresh, (5, 5), 2)
img_canny = cv2.Canny(img_blur, 0, 0)
return img_canny
def get_contours(img):
contours, _ = cv2.findContours(process(img), cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
r1, r2 = sorted(contours, key=cv2.contourArea)[-3:-1]
x, y, w, h = cv2.boundingRect(np.r_[r1, r2])
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
crop = img[y:y+h, x:x+w]
cv2.imwrite('result.png', crop)
get_contours(img)
cv2.imshow("img_processed", img)
cv2.waitKey(0)

есть ли простой способ для дальнейшего распознавания на ней текста?
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract'
print(pytesseract.image_to_string('result.png'))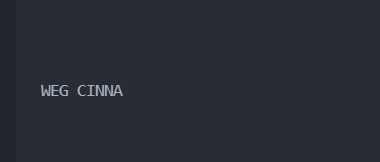


Наружу его пускать нельзя, должен быть nginx
И nginx и Kestrel - веб серверы. Их даже иногда сравнивают.
Но nginx это на порядки более надежный и проверенный сервер, с кучей плагинов и настроек.
Какую роль он играет и почему без него нельзя обойтись?

Range, чтобы качать нужную часть. Но какой толк, если ты одну часть и так качаешь на максимальной скорости. 


Например зависать на полминуты при сохранении маленького текстового файла. Как это лечить я не понял



