Возможно ли получить уникальный идентификатор файла?
Хочу создать навигацию по файлам (просто перекрёстные ссылки в документе), чтобы при этом можно было изменять содержимое файла, переименовывать его, перемещать в другие директории, но чтобы ссылки оставались рабочими.
Как я себе это представлял: при создании файла появляется возможность установить некую "метедату" или получить выданный системой идентификатор (ИД), который остаётся к нему привязан в течение всего "срока жизни". При формировании ссылок, я указываю ИД, а по окончании редактирования, например, перед пушем в репозиторий, запускаю скрипт, который просматривает файлы по ИД и устанавливает на них корректные ссылки в тексте основного документа.
Потратил сегодня много времени на гуглёжку, но не смог найти подходящего решения этой задачи, потому что всё свелось к inode и UUID.
inode показал себя весьма ненадёжно - он изменялся после редактирования файла, да и если потом мой проект кто-то развернёт на другой виртуалке, то иноды пересчитаются под ту файловую систему. При удалении файла инод переназначается новому файлу. Ненадёжно, это не то.
UUID выглядит, как отличная альтернатива уникальной идентификации, однако, я так и не нашёл способа увидеть UUID конкретных файлов.
Подумал, что, возможно, смогу устанавливать некие пользовательские метаданные (а-ля data-attributes в HTML), но оказалось, что это очень ограниченная область и далеко не все инструменты могут работать с метаданными. Дополнительная сложность в том, что скрипт автоматизации хотелось написать на знакомом мне ЯП -- JS или PHP, но в документации последнего я так же не нашёл никаких способов помечать файлы некими уникальными идентификаторами.
Записывать ИД первой / последней строкой в файл можно конечно, но это такое себе. Можно с таким же успехом просто давать файлам уникальные имена, это не интересно. Из обходных путей - повесить демона, который будет отслеживать изменения в реальном времени, но он будет работать только в том случае, если человек развернул виртуалку, а для редактирования документов этого могут и не делать. Можно что-то прикрутить к гиту, чтобы на него повесить эту задачу, но опять же нужно знать что и как. Да и я не верю, что моя хотелка уникальная, всё это уже должно было быть решено сто раз.
Ещё пробовал жёсткие / символические ссылки, но при перемещении файла жёсткая ссылка начинает выдавать при чтении информацию из прошлой версии. Похоже на некое кэширование, не знаю, имеет ли смысл с этим бороться.
В общем, сформировался примерно такой образ:
Уникальный идентификатор, независящий от файловой системы, записанный на том уровне, откуда его возможно получить без танцев с бубнами, но и не на "видном месте", не изменяющийся при перемещении, переименовании файла и изменении его содержимого. Желательно, чтобы не требовал активного демона.
Где взять, как сформировать? Если есть уже готовые решения, то делитесь ссылочками, но интересует и самому слегка разобраться )
После прочтения вопроса интуитивное ощущение, что задача решается принципиально не с того конца. Зачем все это? Почему меняются места и имена файлов, на которые ставится ссылка? Как какая-то навигация будет сохраняться при совершенно от нее не зависящих действиях с диском? Что можно считать одним и тем же файлом, если файлы могут быть одинаковыми, а перемещение может быть копированием и удалением оригинала? Что вам, собственно, на самом деле нужно?
Adamos, да, задача возникла из-за того, что нет проекта - никто точно не знает какая будет структура каталогов, что вообще будет записываться в файлы и какие они получат имена. Но я точно знаю, что будет много текстовых файлов и читать их будет нужно не в алфавитном порядке, а в заданном некой логикой.
В настоящее время, когда файлов чуть больше десятка, нет потребности что-то мудрить, но я боюсь, что однажды, например, через год, придётся внести небольшое изменение в структуру и внезапно отвалятся сотни ссылок.
Возможно, этого никогда не случится или проблемы по перелинковке не возникнет, т.к. я обойдусь парой-тройкой регулярных выражений. Но сама идея идентификации файла в момент создания без привязки к его имени, каталогу или содержимому показалась мне максимально простой и очевидной. Поскольку самостоятельно я не определил насколько это адекватная мысль, я и сформулировал то, что есть на данный момент.
Для копирования файлов нет особой причины, т.к. всё версионируется, а вот может быть такое, что виртуалку с документацией помимо меня склонирует кто-то ещё для совместной работы.
Сергей Мелодин, мне представляется не менее простой и очевидной идея класть файл при создании в предопределенное место, а если потом захочется их как-то реорганизовать или сделать выборку - так для этого, черт возьми, вы и делаете какую-то там систему НАД ними. Просто забудьте о том, что к файлам можно будет получить доступ как-то иначе - и ваша проблема исчезнет автоматически.
Adamos, над файлами ничего нет пока что, это просто документация, написанная не одним большим файлом, а множеством мелких с перекрёстными ссылками. Вот как раз моя мысль об автоматизации перелинковки средствами уникальных ключей - это и есть планируемая система НАД ними.
Если я правильно понимаю, то она вам не нравится (да и у меня пока есть сомнения об её успехе), но какой путь вы предлагаете, я пока не улавливаю ) Повесить на главной странице дисклеймер "редактируй файлы только в PhpStorm"?
Сергей Мелодин, если это документация (то есть текст и картинки), на кой ляд вообще хранить ее в файлах?
CMS научились хранить это добро в базе лет десять назад.
Я предлагаю не городить сложные связи между не зависящими друг от друга уровнями.
Это элементарное правило вменяемой архитектуры.
Так же, как обеспечение консистентности информации работой с ней только через одну точку входа.
Ваша идея пока смутно очерчена, и только поэтому она кажется вам разрешимой.
Подробности ее проработки будут постоянно требовать новых костылей и преодоления.
Но сама идея идентификации файла в момент создания без привязки к его имени, каталогу или содержимому показалась мне максимально простой и очевидной.
И что тут очевидного?
Файл это именованный блок информации. Две главные и обязательные сущности файла это имя и содержимое.
Вы хотите не привязываться ни к одной, ни к другой.
Этим вы исключаете привязку к файлу.
Если нет привязки к файлу - непонятно тогда вообще в чем проблема, и для чего это.
АртемЪ, смотря что имеется в виду под изменением - перемещение, переименование? Возможно, что никогда. А вот контент вполне может меняться из-за опечаток, недостатка информации, устаревания и т.п.
АртемЪ,
> непонятно тогда вообще в чем проблема
Я не знаю, почему тут для всех это проблема, кроме Александра (чей ответ отмечен решением). Есть два решения для трёх популярных ОС + тот же inode. Теоретически получается возможным привязаться к файлу, не цепляясь за имя/содержимое/путь. Всё, что мне остаётся - прогуглить эту тему чуть подробнее, сделать пару-тройку экспериментальных файлов и если это окажется совсем неудобный костыль, то я просто поставлю в гите права так, чтобы все изменения в файлах шли через мерж-реквесты и буду сам контролировать.
Проблема, собственно, не "для всех", а для вас - отвечающим очевидно, что вы городите удивительные велосипеды вместо поиска простых и естественных путей.
Это, конечно, интереснее... но в качестве рабочего решения, увы, не годится.
Adamos, пока ничего не горожу, а опираюсь на существующую систему и хочу использовать её в своих целях. Не вижу в этом чего-то экстраординарного, проблема только в универсальности и доступности. Выделил всё это в отдельное обсуждение: https://toster.ru/answer?answer_id=1279499#answers...
Записывать ИД первой / последней строкой в файл можно конечно, но это такое себе. Можно с таким же успехом просто давать файлам уникальные имена, это не интересно.
Александр Таратин, extended attributes? Чёрт, я сегодня рядом с ними находился, но ушёл от слова "атрибуты" к "метаданным" и в итоге потерял нужную нить )
Есть ли у вас личный опыт их использования? Интересует, стоит ли овчинка выделки.
Полагаю, что если строить свою ИС (инф. сист.) поверх прослойки, работающей посредством FUSE, то все упростится.
В своей нижележащей ФС можно назначать файлам UUID. Файл - это некий объект, с которым может быть ассоциирована такая служебная информация, как имя файла или URI, в общем виде, которые подвержены частым изменениям. Набор таких объектов хранить в некой СУБД (допустим, SQLite).
При монтировании хранилища посредством FUSE в какую-нибудь директорию наружу будут видны как обычные файлы. При изменении имени файла меняется только служебная информация об объекте в хранилище. Хранилище может быть как локальное, так и удаленное. При удалении файла-документа в хранилище можно пометить объект как подлежащий утилизации или же просто удалению. При изменении версии файла-документа меняется содержимое объекта в хранилище. В служебной информации (meta data) можно также хранить хэш от содержимого.
Готового решения под ваши запросы нет, и в ближайшее время не предвидится.
Сейчас есть множество файловых систем, которые не сохранят ваши супер-метки, и вся красивая задумка разрушится.
Для разминки можете представить что будет, если файл заархивировать, а затем распаковать.
Если создать несколько копий одного файла - на какой из них будет указывать ваша суперссылка?
Если переписать файлы на флешку с fat32 а затем обратно?
Передать по сети?
Вообще для решения этой проблемы придумали URI, но работает, опять-же, не везде и не всегда.
Разминка притянута за уши (как и моя тема, в общем-то), не представляю, чтобы из открытого репозитория (в рамках одной организации) кто-то захотел скачивать исходники и передавать их по сети в архиве )
Поскольку разные люди в разных местах пишут на одну и ту же тему, я сокращу изначальный текст:
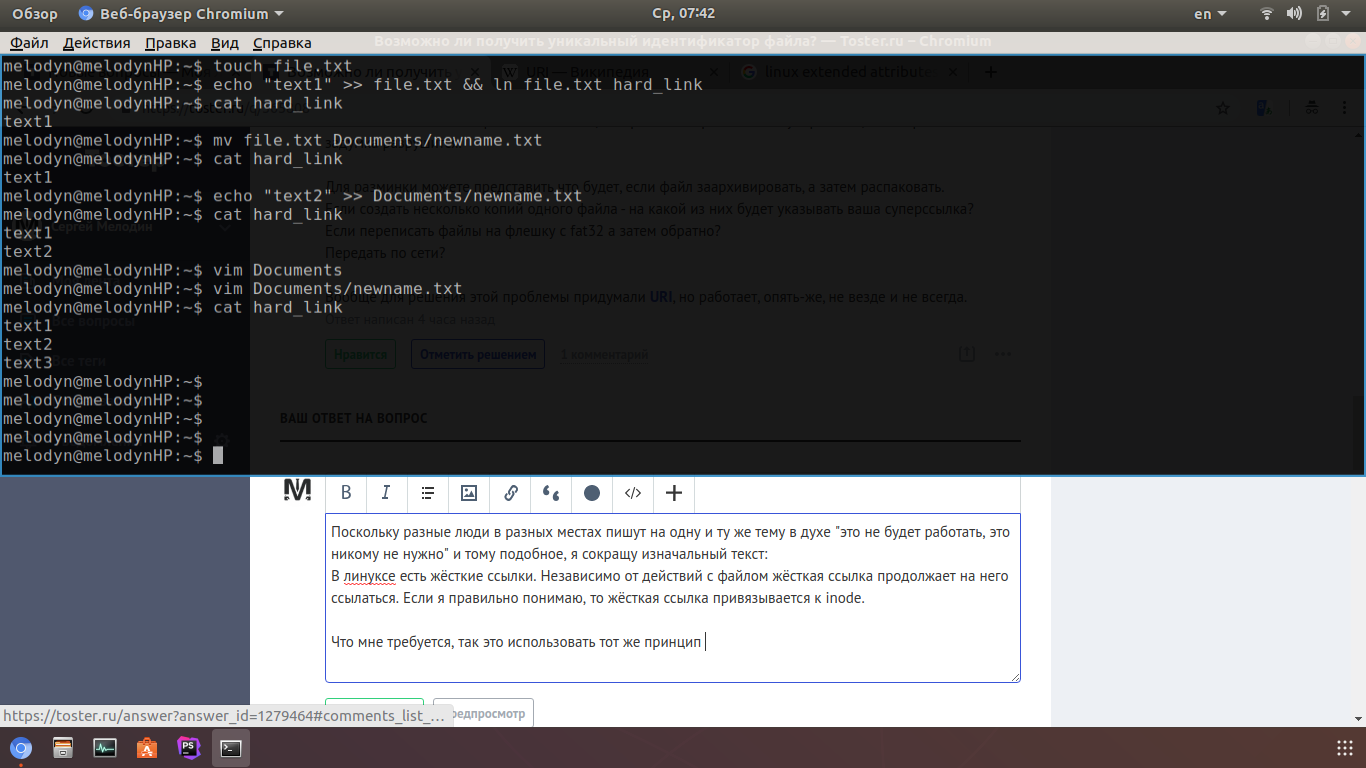
В линуксе есть жёсткие ссылки. Независимо от действий с файлом жёсткая ссылка продолжает на него ссылаться. Если я правильно понимаю, то жёсткая ссылка привязывается к inode, который ведёт себя несколько непредсказуемо. Например, на домашнем ПК при изменении файла жёсткая ссылка работает корректно:
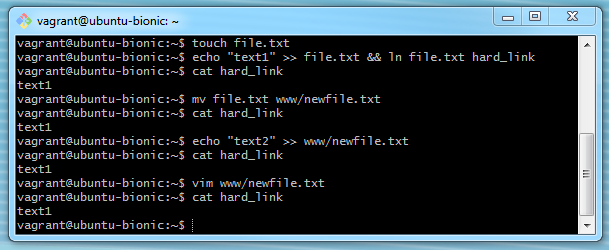
но на рабочем ПК почему-то изменения файла приводят к изменению инод и жёсткая ссылка уже отображает неверное содержимое файла:
Видимо, связано с тем, что в случае с виртуалкой, система работает с файлами иначе, опираясь на файловую систему родительской машины.
Если у меня получится обеспечить поведение жёсткой ссылки независимо от местонахождения, то это позволит создать, например, каталог links, помещать туда жёсткие ссылки под уникальными именами, в коде указывать ссылку по типу [следующий файл](#my_awesome_hard_link) и задача решена.
Поэтому говорить о том, что это никому не нужно, не существует в природе или "чё ты придумал такое, лол", честно говоря, такое себе.
но на рабочем ПК почему-то изменения файла приводят к изменению инод и жёсткая ссылка уже отображает неверное содержимое файла.
Многие редакторы при сохранении файла сначала сохраняют его в новый файл , затем переименовывают старый файл , переименовывают новый и только потом удаляют старый файл. Делается это, чтобы при сбое записи не потерять содержимое файла.
Rsa97, я думаю, дело не в редакторе, а в том, что на рабочем ПК виртуалка с Убунту, а основная система - Винда, будь он не ладна. И из-за этого происходит данный косяк, ибо на виртуалке даже дописывание в файл через >> даёт такое же поведение.
Но о проблеме с редакторами я в курсе, но если получится разрешить проблему с ссылками, то останется только вопрос к PhpStorm - страдает ли он такой болезнью, как пересоздание файлов. Ибо редактировать документацию буду или я, или разработчики, а мы все работает в Шторме.
Сергей Мелодин, боги! вы еще и экспериментируете с папкой, проброшенной в виртуальную машину...
Советую при дальнейших экспериментах надевать маску сварщика. Так будет еще интереснее.





 Средний
Средний





