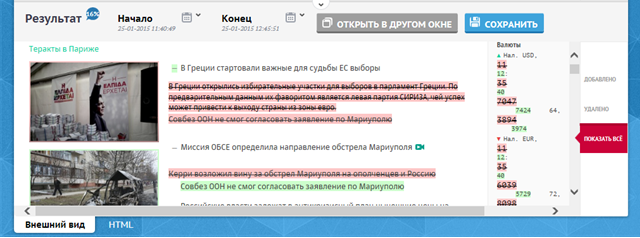
Как сделать простое текстовое сравнение понятно
А вот и совсем не понятно, потому что текстового сравнения HTML там нет. Страница сначала полностью парсится, потом идет по-элементное сравнение всех текстовых элементов. Если
расстояние меньше константы, элементам присваивается единый uid (то есть они признаются парой вариантов одного элемента). Для других тегов, содержащих в себе текст оценивается относительный объем совпадающих дочерних текстовых элементов, на основе этого производится их идентификация, и так идет проход снизу вверх, пока не соберется общее дерево. А сама раскраска diff-отличий для сопоставленных текстовых элементов - тривиальная задача.
Я хорошо знаю эту тему, потому что однажды писал подобное. Тема сложная, готовых решений нет, универсальных подходов тоже нет (мое описание упрощено на порядок), куча разных граничных случаев, мозг закипает от одной только декомпозиции задачи. В общем я так и не закончил решение в тот раз, спонсор потерял веру в проект, а без финансирования на голом энтузиазме такого масштаба проекты не заканчиваются в одиночку. До сих пор мечтаю продолжить, пусть на других технологиях, но с большим опытом в этой теме.