Представим такой упрощенный код, интерпретатора шитого кода.
Вопрос, на которой не могу найти ответа. Когда эмулятор собирает и компилирует код jit,
то как он этот код в машинных инструкциях составляет. Ведь если запустить такой код 1в1 соотношений инструкций, или более оптимизированный даже, есть прерывания, есть некие интерфейсы чью логику нужно поддерживать. (а невозможно выйти из выполнения клинского кода, если только в самом клиентском коде, не будет спец. инструкций переключения, проблема остановки наверное)
Ведь ему надо к примеру
Перед выполнением каждой инструкции проверять наличие прерывания
А значит ему нужно компилировать код, вставляя через инструкцию, инструкцию проверки выполнения условия, и инструкцию перехода. В общем минимум 3 инструкции.
Плюс там наверное, еще нужно поддерживать эмуляцию разных устройств.
На псевдокоде простой интерпретатор будет как-то так, куча проверок перед каждым выполнением,
но статистически известно, что прерывание вещь редкая, но требует мгновенной реакции(или вопрос на эмуляторах она не требует мгновенной реакции).
while(env->pc>0){
if(env->IsInterrupt){
pic->Interrupt();
}
code[pc].Execute(param[pc]);
}
Я придумал, к примеру, вшить проверку прерываний, в некоторые инструкции. Я читал
while(env->pc>0){
code[pc].Execute(param[pc]);
// некоторые инструкции имеют в теле проверку прерываний
// все инструкции перехода, деления
}
Я читал "Программное моделирование вычислительных систем Учебное пособие", там я я не нашел конкретный ответ, либо я его не понял.
Но там было типа написано, что типа надо проверять после каждой инструкции, что не оптимально, либо же делать Callback когда нужно, но без конкретики.
Еще вопрос из теории графов потока управлений итд.
При генерации блоков кода, этот код весь линеен, то есть все инструкции программы друг за другом выполняются? В таком случае, все в один массив записывается, но тогда, короче, после некоторых инструкций перехода, будет так, что инстурукция ниже будет к другому коду относится, и тогда у этой инструкции перехода будет if(cond) прыжок в одно место, else в другое,
вместо просто PC+=1(для примера выше)
Или же есть несколько блоков, где линейно выполняется весь блок, а последняя инструкция прыгнет в другой блок. Тогда можно представить в контексте примера, как несколько массивов code.
К примеру есть такой граф. Цифрами будет обозначен порядок прохождения
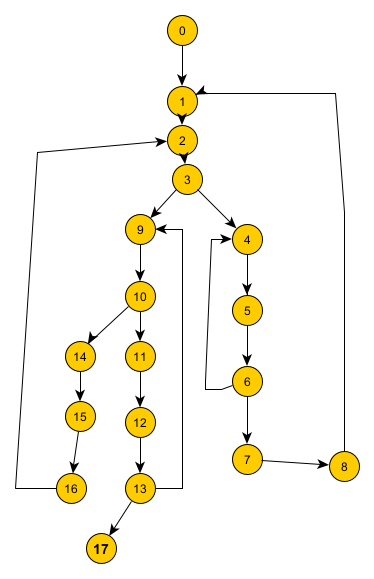
Если все строить в один последовательный массив, то будет построен такой код,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17. Из графа видно, что после блока 13 есть переходы на 9 или на 17, а не на след за ним 14, что усложняет. (я эту ошибку очень долго найти не мог, пока не понял)
Я читал, и вроде как делаются разные блоки, типа трассировки, и после проождения одного происходит переключение на другой(но не особо понял), к примеру для вот такого примера графа, сколько базовых блоков можно построить?


 Средний
Средний





