Суть вопроса. Есть данные о вероятности встретить некоторый вид в зависимости от высоты над уровнем моря:
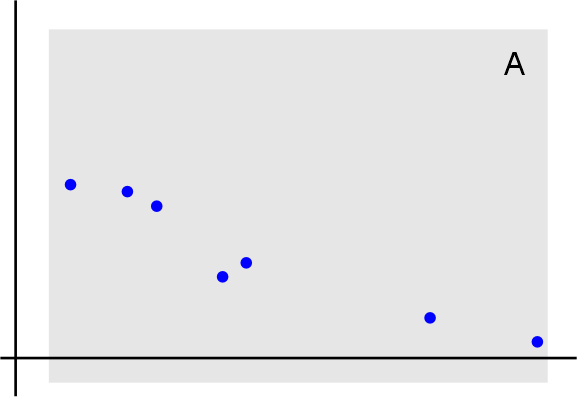
Серым фоном показан диапазон высот где в принципе проводились поиски, т.е. он ограничен.
Нужно найти точку максимальной распространенности вида (т.е. на какой высоте его больше всего).
Так как распределение нормальное, то по сути нужно найти центр этого нормального распределения.
Стандартные функции определения нормального распределения по выборке, предполагают, что оно равно мат. ожиданию выборки. Т.е. как-то так:
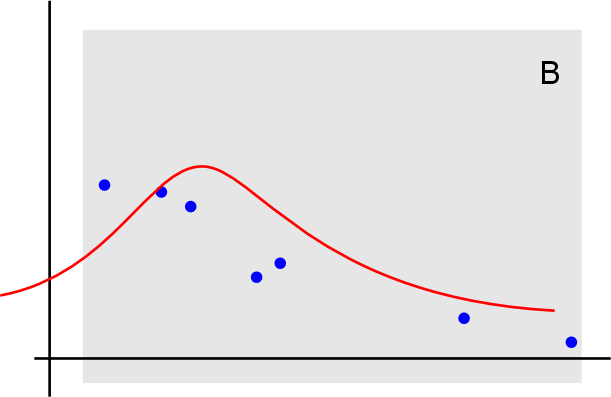
Но это не учитывает, что центр может быть за пределами анализируемого диапазона. И в данном случае, данные гораздо лучше аппроксимируются как-то так:
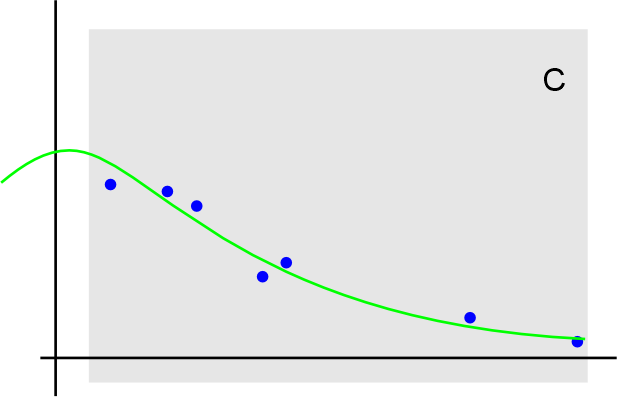
Для нахождения параметров такого распределения я написал небольшой скрипт на питоне который тупым перебором параметров нашел нужные распределения. И результат неплох, в смысле соответствует представлениям о реальном характере произрастания растений. Но возникло два вопроса:
1. Как на деле определяются параметры такого смещенного нормального распределения? Может есть стандартные функции/алгоритмы для аналитического решения задачи?
2. (и главное) Как это все описать правильным с т.з. мат. статистики языком? Мне нужно изложить весь алгоритм в статье, а я довольно далек от мат. статистки, и боюсь переврать термины. Можете подкинуть какие-то правильные формулировки, для этого случая?
Понимаю, что совет "возьмите учебник такой-то и за полгодика освойте основы" - классный и очень приятный советующему. Но надеюсь на помощь людей живущих в реальном мире и понимающих, что возможности не всегда совпадают с желаниями.
В любом случае, спасибо, за любые советы!


 Средний
Средний
 Средний
Средний

