зачем тебе тогда tor? в твоей схеме он может помочь только пробиться через локальные ограничения провайдера (или провайдера, где находятся 'твои ip')
еще момент, ip адрес это один из огромного количества источников 'отпечатков браузера'. окружение (установленный софт, железо и поведенческие факторы) дают больше информации о клиенте.
_pconnect реализация обычно для всех БД так как php подразумевает многократное завершение и перезапуск, чтобы подключение не переоткрывалось, но в этом режиме бессмысленно под разными пользователями заходить, скорее всего кеш просто не будет использоваться и каждый раз будет переподключаться
про пул - изучай сам, я этим не пользовался.
про скорость - когда то давно именно для публикации в веб данных из базы oracle приходилось ставить между бакэндом и ораклом 'кеширующий' mysql
просто без гуглиннга в какой кодировке нужно отправлять sms предлагаю тебе просто принять на питоне той же библиотекой sms с русским и посмотреть что там за кодировка
еще момент у llama очень маленькое окно контекста, кажется 2к токенов, это ее фатальная проблема, из-за которой для сохранения контекста ее лучше дообучать под каждую задачу.
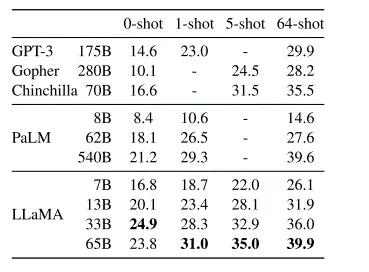
Если говорить хочешь с позиции циферок, то лучше сравнивать не размеры пис*к, а то гугловский PaLM 540B должен всех победить а он просто на среднем уровне находится (иногда хуже ламы)
p.s. у меня есть мнение что фейсбуке сделала намеренно сеть публичной, так как осознают что ее качество низкое, выкидывать просто так жалко (деньги закопать) а так хоть какой то пиар эффект будет, а если сообщество сумеет запилить что то полезное, можно пальцем погрозить и платить заставить, забрав наработки себе само собой.
Hemul GM, а вы пробовали gpt?
напоминаю, chatgpt это продукт, созданный с использованием gpt (у openai несколько моделей доступны по api), там текст не отправляется тупо в языковую модель (или к примеру отправляется модифицированным сразу в несколько для классификации например), так же модель должна быть предварительно подготовлена, один из лучших способов улучшения ответа сырой языковой модели - добавление предварительного текста к вопросу, например бенчмарки используют технику one-shot (добавляют к вопросу спереди другой вопрос с ответом, так сеть на основе примера понимает что от нее хотят)
p.s. https://www.inovex.de/de/blog/prompt-engineering-guide/
есть разные базы и алгоритмы данных для сравнения больших языковых моделей (гуглить картинки с таблицами - quality comparison ai big language models palm lambda gpt3 llama)
V0VA, в таких ситуациях НАСТОЯТЕЛЬНО РЕКОМЕНДУЕТСЯ при получении данных не запускать их обработку, а складировать в хранилище fifo, даже на основе файлов, кода 5-6 строчек.
А саму обработку делать отдельным приложением, читающим эти файлы
zkrvndm, да такая схема сработает, переименование у тебя захват монополии на запись.
Совет, временное имя файла должно содержать pid процесса, в него пишущее, чтобы если этот процесс помрёт, остальные не ждали его вечно (предусмотри демона, моняторящего это)
zkrvndm, осторожно, речь идёт о завершении записи другим потоком, если ты в этот момент переименуешь файл, предыдущий поток про это не узнает и без преград продолжит писать
Что не понятно? Создаешь второго пользователя, подключаешься к нему из дома, затем из него запускаешь удаленный рабочий стол' и подключаешься по localhost под основным пользователем, теперь когда ты будешь отключаться от сессии того дополнительного второго пользователя, главная сессия останется подключенной
Ты не понимаешь идеи асинхронного программирования, в ней ту тебя код отстаивает не в том порядке, что записан, а код обработки события, где нужен твой userid должен быть внутри этой анонимной функции
Sergey В., ты абсолютно прав, но с пользовательской точки зрения, нет никакой разницы, VBA там или VBSript, в контексте задачи они похожи и отличаются обрамлением кода и инициализацией, ну интерфейс по разному описывается. Человеку нужно задачу решать, если он смог ее решить на VBA, значит используя эти знания он легко сможет продолжить работу в MS VS и даже с использованием VBS, благо везде там для работы с документами используется один и тот же фреймворк/класс COM от оффиса
DragoN DragoN, мысль у Александр Маджугин, собирать больше информации о статье, в машиночитаемом виде
просто дата и приблизительное место, позволит делать поиск не по всей базе а на интервале дат
я бы сюда закинул источник, собрав какой то объем статей и откидывая в ручном режиме дубликаты, сам факт этого откидывания тоже нужно сохранять (т.е. сохранять статью с пометкой - дубликат другой статьи, с указанием какой), и на основе этой информации можно принять решение о том что такой то источник плодит исключительно дубликаты и его можно не использовать
Sergey В., не понимаю в чем я создал путаницу? я даже ссылку на подробное описание в документации разницы дал, на русском.
Отлично помню как много лет назад я писал автоматизацию оффисного документа именно на c#, (а мой сосед копировал кусками в свой проект блоки из офисного VB в VB.NET), и я не про работу с экселем как с таблицей, нет, именно как документ, работая с ячейками точно так же, какой код генерирует автосоздание макросов в оффисе.
upd. моя ошибка, windows scripting host, в котором можно писать код на VB в т.ч. не поддерживается студией, я просто помню как писал его в FAR commander и запускал штатной утилитой cscript, внутри подключал библиотеку офиса и работало
зачем тебе тогда tor? в твоей схеме он может помочь только пробиться через локальные ограничения провайдера (или провайдера, где находятся 'твои ip')
еще момент, ip адрес это один из огромного количества источников 'отпечатков браузера'. окружение (установленный софт, железо и поведенческие факторы) дают больше информации о клиенте.