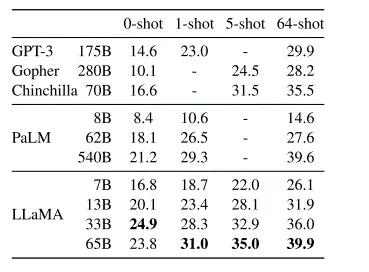
Благодаря 'публикации' в интернете весов языковой модели LLaMa а так же таким проектам как
llama.cpp появилась возможность поиграть с большим ИИ не в облаке от openai да еще и на дешевом оборудовании на процессоре (64Gb ram использую 65B модель с 4bit quantize).
Судя по тому как меняется качество 'ответов' сети в зависимости от построенного запроса, есть какое то правило, на основании которого исследователи facebook строили обучающие данные для этой модели. В частности такие ключевые слова как ### Instruction: ### Input: ### Question: в конце должен стоять ### Response: ### Answer:, и количество \n перед/после них и запроса тоже важны (долго не мог понять почему если я свой запрос делаю в одной строке с этими ключевыми словами или с одним \n сеть почти всегда несет пургу). Еще в моменты бреда, модель начинает выдавать другие ключевые слова как ### Explanation: ### Annotation или ### Output
Отсюда вопрос, нет ли какой то полной инструкции по форматам запросов, или возможно кто то уже исследует возможности и нашел закономерности? Очень уж качество разительно меняется, если ей задавать ожидаемую ей разметку.
p.s. у ggerganov в github в ветке mmap-preload загрузка весов модели переделана на mmap, т.е. они теперь хранятся в кеше ОС и при повторном запросе время на их загрузку не тратится (можно одновременно запустить два приложения)

 Простой
Простой