Могут загружаться, а могут и нет. JVMS не определяет должны ли загружаться все, часть или вообще никакие типы, на которые ссылается загружаемый класс. Так что данное поведение остаётся на усмотрение разработчика JVM.
HotSpot, например, реализует ленивую загрузку классов. То есть не загружает классы, если в этом нет строгой необходимости. Он может даже не все static члены загрузить во время статической инициализации класса.
Пример:
import java.time.LocalDateTime;
import java.util.concurrent.CountDownLatch;
public class A {
private static LocalDateTime ldt;
private static CountDownLatch cdl;
static {
ldt = LocalDateTime.now();
cdl = null;
}
public static void main(String[] args) {
System.out.println("123");
}
}
При запуске данного кода с аргументом JVM "-verbose:class" выведется список всех загруженных классов. Пример запуска на openjdk 12:
...
[0,100s][info][class,load] java.time.temporal.TemporalAccessor source: shared objects file
[0,100s][info][class,load] java.time.temporal.Temporal source: shared objects file
[0,100s][info][class,load] java.time.temporal.TemporalAdjuster source: shared objects file
[0,101s][info][class,load] java.time.chrono.ChronoLocalDateTime source: shared objects file
[0,101s][info][class,load] java.time.LocalDateTime source: shared objects file
...
Видно, что загрузился LocalDateTime и все имплементируемые им интерфейсы, но CountDownLatch в списке отсутствует, несмотря на то, что существует статическая переменная с этим типом.
Аналогично происходит и с instance членами - классы, на которые они ссылаются, будут загружаться только по мере необходимости (использования). Вполне нормальна ситуация, когда объекты одного класса активно используются в программе, но при этом не все используемые им типы загружены. Более того, это относится не только к членам класса или объекта, но и к локальным переменным и даже просто коду:
import java.math.BigDecimal;
import java.time.LocalDateTime;
public class A {
public static void main(String[] args) {
if ("world".equals(System.getenv("HELLO"))) {
System.out.println(LocalDateTime.now());
} else {
System.out.println(BigDecimal.TEN);
}
}
}
В этом примере будет загружен класс BigDecimal, но не LocalDateTime. Если инвертировать условие или запустить код с выставленной переменной окружения HELLO=world, то в списке классов появится LocalDateTime, но BigDecimal будет отсутствовать.


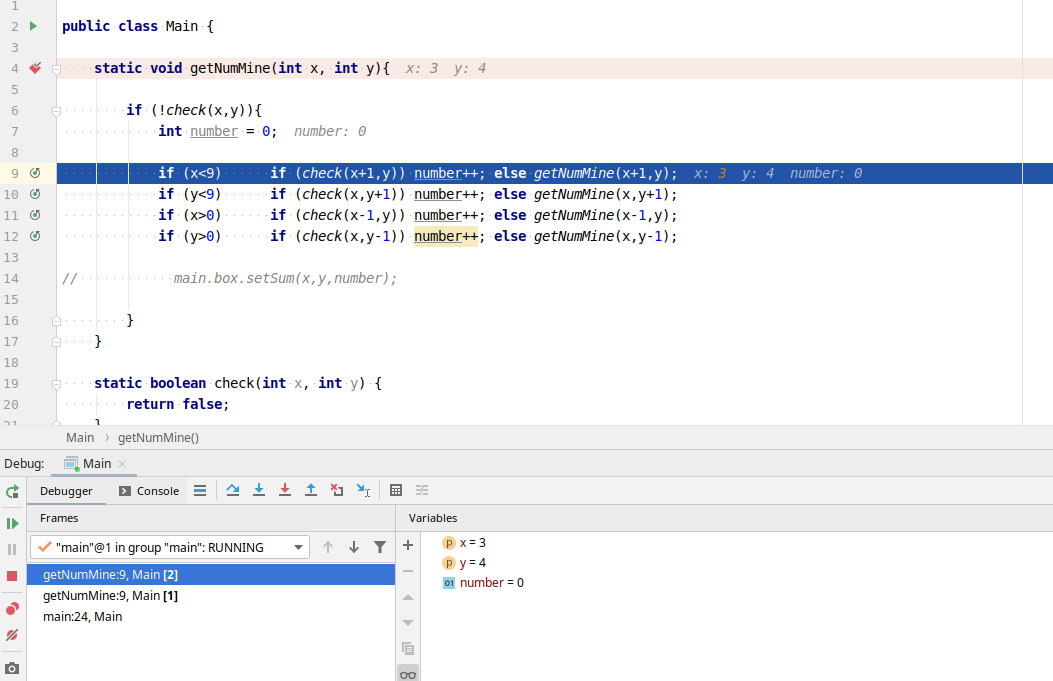 (на скриншоте я уже проехал несколько шагов вперёд)
(на скриншоте я уже проехал несколько шагов вперёд)