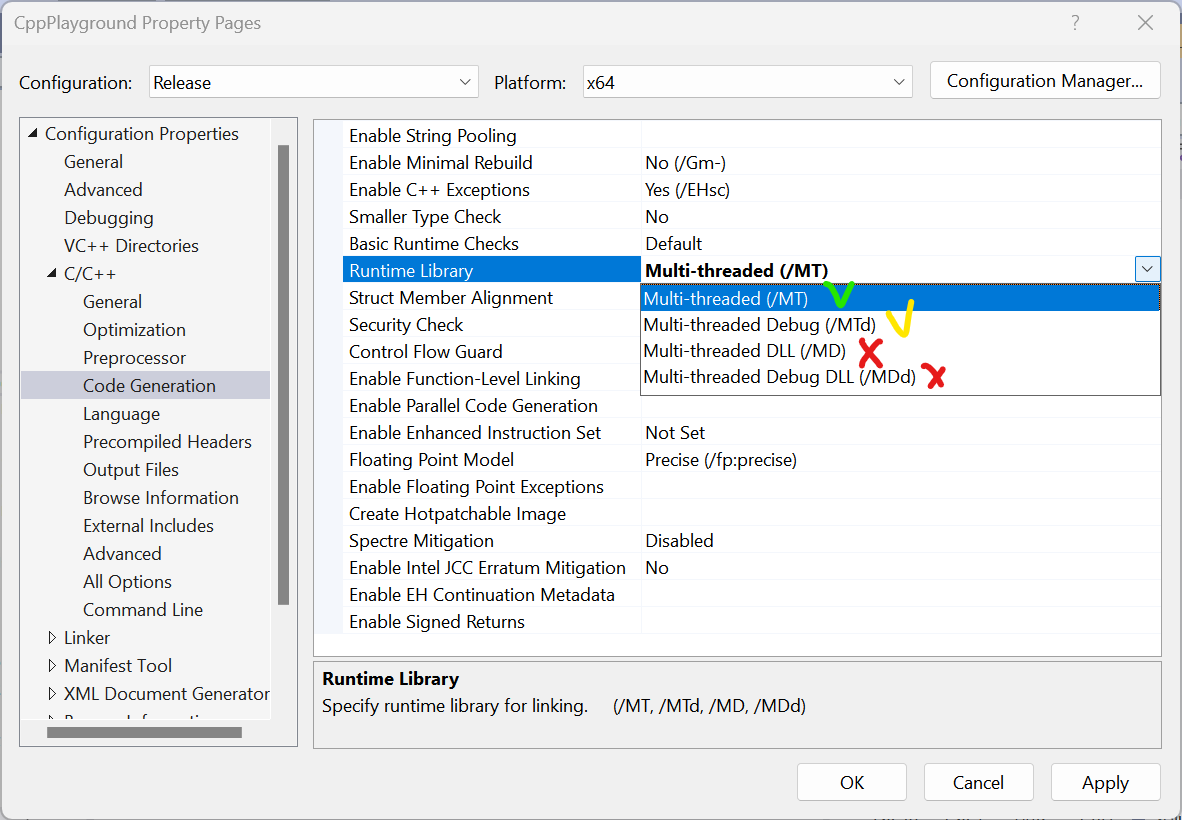
#include <string>
#include <string_view>
#include <ranges>
#include <array>
#include <utility>
#include <algorithm>
#include <cassert>
#include <stdexcept>
template <typename Key, typename Value, std::size_t Size>
struct Map {
std::array<std::pair<Key, Value>, Size> data;
constexpr Value at(const Key key) const {
const auto iter = std::find_if(std::begin(data), std::end(data),
[&key](const auto& v) { return v.first == key; });
if (iter == std::end(data)) {
throw std::range_error("unknown character");
}
return iter->second;
}
};
static constexpr std::array<std::pair<std::string_view, char>, 51> MORSE_MAP = { {
{"•-", 'A'}, {"-•••", 'B'}, {"-•-•", 'C'}, {"-••", 'D'},
{"•", 'E'}, {"••-•", 'F'}, {"--•", 'G'}, {"••••", 'H'},
{"••", 'I'}, {"•---", 'J'}, {"-•-", 'K'}, {"•-••", 'L'},
{"--", 'M'}, {"-•", 'N'}, {"---", 'O'}, {"•--•", 'P'},
{"--•-", 'Q'}, {"•-•", 'R'}, {"•••", 'S'}, {"-", 'T'},
{"••-", 'U'}, {"•••-", 'V'}, {"•--", 'W'}, {"-••-", 'X'},
{"-•--", 'Y'}, {"--••", 'Z'}, {"-----", '0'}, {"•----", '1'},
{"••---", '2'}, {"•••--", '3'}, {"••••-", '4'}, {"•••••", '5'},
{"-••••", '6'}, {"--•••", '7'}, {"---••", '8'}, {"----•", '9'},
{"•-•-•-", '.'}, {"--••---", ','}, {"---•••", ':'}, {"••--••", '?'},
{"•----•", '\''}, {"-••••-", '-'}, {"-••-•", '/'}, {"-•--•", '('},
{"-•--•-", ')'}, {"•-••-•", '"'}, {"-•••-", '='}, {"•-•-•", '+'},
{"-••-", 'x'}, {"•--•-•", '@'}, {"/", ' '} } };
constexpr auto decode(std::string_view morse) {
constexpr auto map = Map<std::string_view, char, MORSE_MAP.size()>{ MORSE_MAP };
return morse
| std::ranges::views::split(' ')
| std::ranges::views::transform([](auto&& range) {
return map.at(std::string_view{ range });
})
| std::ranges::to<std::string>();
}
int main() {
const auto CODE = "•••• • •-•• •-•• --- --••--- / •-- --- •-• •-•• -••";
const auto TEXT = "HELLO, WORLD";
assert(decode(CODE) == TEXT);
return 0;
}