

f = pd.DataFrame({
'A':['a',np.NaN,np.NaN,'b',np.NaN,np.NaN,np.NaN,'v',np.NaN,np.NaN,'d',np.NaN,np.NaN],
'B':['foo','foo','bar','bar','bar','foo','bar','foo','bar','foo','bar','foo','bar']
})
result = (
df
.groupby(df['A']
.fillna(method='ffill'))['B']
.apply(lambda x: ','.join(x))
.reset_index()
)
result(
df.
assign(latest=lambda x:x
.groupby("some_name")["date_time"]
.transform(pd.Series.nlargest, 1)
)
.loc[lambda x: x['date_time'] == x['latest'],:]
)import re
searchstr=(
ff.loc[ff['B']
.str.contains(r'строка',regex=True,flags=re.IGNORECASE),['А','B']
]
)return int(answer) выхода из функции не происходит (только рекурсивный вызов остановлен). python идет дальше, пропускает else, затем у функции отсутствует return и он возвращает None.return gen_nums(stop_n, number)
empty_sets = []
for _ in range(3):
empty_sets.append(set())
for obj in empty_sets:
print(id(obj))a = set()
b = set()
a is bfor _ in range(3):
print(id([]))for _ in range(3):
print(id(list()))import itertools
[list(itertools.chain.from_iterable(x)) for x in (list(itertools.product(A,B)))]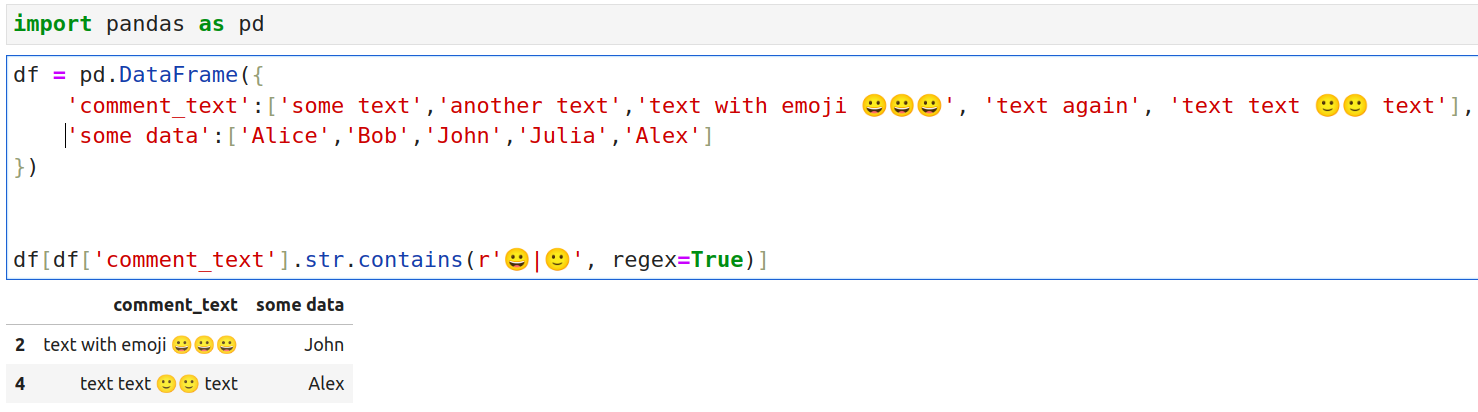
df[df['comment_text'].str.contains(r'[^\w\s,]', regex=True)]def test(n, rez = None):
if rez is None:
rez = []
for i in range(n):
rez.append(i)
return rezdf['predictions'] = (
model
.predict(X)
.replace({0:'Метка ассоциируема с 0', 1:'Метка ассоциируемая с 1'})
)low = df['Age'].quantile(0.05)
upper = df['Age'].quantile(0.95)
df[df['Age'].between(low, upper)]np.percentile()
plt.xticks(range(2006,2023)) Второй параметр в данном случае тебе не нужен. Глянь пример из доков, также. Да и имей ввиду если ты используешь ооп апи, работаешь с объектами axes, то там set_xticks и set_xticklabels. То есть на два метода этот функционал разбит, например https://www.geeksforgeeks.org/matplotlib-axes-axes...
for i in time:
data = change_data(i)benz_df['time'] = data колонке time, значение data. Он его броадкастит на всю колонку да и все. Ты ожидаешь что data это массив c данными, а это одно значение. data= []
for i in time:
data.append(change_data(i))benz = pd.read_xml(benz_xml_file, xpath='.//filling')
benz_df = pd.DataFrame(benz)
benz_df['time'] = benz_df['time'].apply(change_data)
benz_df['time'][:50]