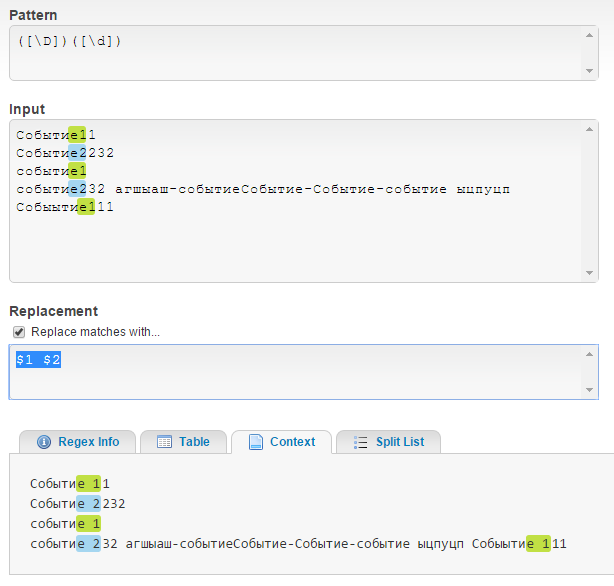
Вы, почему-то, не используете одну из самых мощных фич Хаскелла - типы. Программа гораздо легче пишется, когда вы её сначала написали на уровне типов. Функции после этого пишутся гораздо легче.
Переходя к вашей задаче: я бы разделил её на два этапа.
1. Лексический разбор строки на список токенов.
2. Парсинг списка токенов в выражение.
Какие у вас могут быть токены? Числа, операторы, левая и правая скобки. Вот их и кодируйте в типе Token:
data Token = NumToken Double | OpToken Operator | LeftParenToken | RightParenToken
data Operator = Plus | Minus | Mult | Div
В типе Token конструктору данных NumToken я передал Double, т.к. если у вас будет деление, с Int или Integer вы не сможете его произвести без дополнительной конвертации.
Дальше вы должны превратить вашу строку в список токенов. Это отлично делается рекурсией:
strToToken :: String -> [Token]
strToToken [] = []
strToToken (c:cs)
-- Токенизируем голову списка и вызываем токенизацию на его хвосте
| c == '(' = LeftParenToken : strToToken cs
| c == ')' = RightParenToken : strToToken cs
-- Если встречается пробел - откидываем его и токенизируем строку дальше
| isSpace c = strToToken cs
-- если встречается число, вызываем функцию-хелпер number
| isDigit c = number c cs
-- не забываем о случаях, когда строку не удалось распарсить полностью
| otherwise = error $ "Не могу распарсить " ++ [c]
Функция strToToken и вспомогательная функция number являются взаимно рекурсивными. Из функции strToToken мы вызываем функцию number, а из функции number мы вызываем функцию strToToken:
number :: Char -> String -> [Token]
number c cs =
-- разбиваем строку на цифровые символы, идущие друг за другом,
-- и на остаток строки при помощи функции span
let (digits,rest) = span isDigit cs
-- сразу переводим полученные цифровые символы в число
-- при помощи функции read и токенизируем остаток строки
in NumToken (read $ c:digits) : strToToken rest
Вот вы и сконвертировали строку в список лексем. Следующая задача - парсинг лексем в выражения. Советую точно так же создать тип, содержащий все возможные выражения. Подсказка: этот тип у вас получится рекурсивным, т.к. выражение может состоять из нескольких выражений, разделённых операторами.