Поиск наиболее подходящих наборов из последовательности (очень много сочетаний)
Имеется набор битовых последовательностей фиксированной длинны (L == 1024). Количество последовательностей ~43000.
Как среди них отыскать сочетание из N (N == 10) такое, чтобы количество включенных битов в поразрядном логическом сложении результата было максимальным?
Например (L = 4, N = 2) 0100
0010
0110
1000
1100
Ответом будет: 0110
1100
---- проверяем, какие биты у нас включены
1110
Задача осложнена огромным объемом исходных данных. Количество возможных сочетаний заставляет грустить.
Можно ли решить данную задачу за приемлемое время, либо положиться на случай и запустить на пару суток рандомный алгоритм?
upd
Либо уже я туплю, либо не понимаю предложенные решения. Поиск по максимальному кол-ву битов не даст результата. Иллюстрирую:
L =4, N = 2, для набора
1110 — 3
1100 — 2
0110 — 2
0001 — 1
если посчитаем ко-во бит и отсортируем (возьмем top N), то получится
1110
1100
а нужно
1110
0001
upd2
Для себя решил делать поиском из «лучших результатов»:
L =5, N = 3, для набора
11100 — 3
11000 — 2
01110 — 2
00010 — 1
00001 — 1
0) m = 11111
1) получаем лучшую последовательность для m (11111)
result = [11100]
теперь m = 00011
2) получаем лучшую последовательность для m(00011)
result = [11100, 01110]
теперь m = 00001
3) получаем лучшую последовательность для m(00001)
result = [11100, 01110, 00001]
теперь m = 00000, закончили
получили ответ — [11100, 01110, 00001]
но это не единственное решение (на шаге 2 подходят 01110, 00010, 00001)
если количество исходных данных велико, то «лучших» результатов будет много. и, конечно, не факт, что найдется вообще сочетание, которое покроет все биты(этого мне и не нужно). в природе я получу кучу результатов (если среди «лучших» вариантов буду выбирать случайный). вот из этих-то «лучших» в конечном итоге я и выберу наиболее мне подходящий (отсортирую по кол-ву покрытых бит).
В upd2 верный алгоритм, выбирать из «лучших» можно первый попавшийся, это абсолютно не влияет на получающийся результат. (Если я правильно понял — то Вы сейчас рассматриваете все варианты с различными «лучшими» выбранными на каждом шаге?)
А в чем проблема посчитать биты в последовательности длиной 1024 бита? Они у вас в чем хранятся? Я думаю в конце эта задача сведется к 1024 сдвигов. Загрузите в их в 32 long'а и пробегитесь по массиву.
long[][] myArray = new long[43000][32];
int[] bitsCount = new int[43000];
//загружаем в 32 лонга свою последовательность. 32*4*8 = 1024 бита
<тут ваш какой-то код>
//определяем количество установленных бит
for(int i = 0;i<43000;i++) //цикл по всем последовательностям
for (int j = 0;j<32;j++) //цикл по всем long'ам
for(int k = 0;k<32;k++) //цикл по всем битам лонга
if((myArray[i][j] >> k) & 0x1)
bitsCount[i]++;
//дальше сортируем массив bitsCount и берем N верхних. Или оптимизируем сортировку чтобы она не полностью сортировала, а только искала N верхних
//???
//PROFIT!
Работать будет не очень долго. Уж точно не пару дней. Или я задачу не понял?
давайте еще раз взглянем на пример.
допустим есть набор:
0[...]111[...]0 — сумма бит 3
0[...]111[...]0 — 3
0[...]111[...]0 — 3
0[...]111[...]0 — 3
0[...]000[...]1 — 1
если мне нужно выбрать 2 массива бит такие, чтобы кол-во покрытых бит было максимальным, то сортировка по кол-ву бит не даст ничего. в исходнм наборе они отсортированы. и вот мы выбираем 2 top:
0[...]111[...]0 — сумма бит 3
0[...]111[...]0 — 3
но это не правильный ответ. правильный ответ — это
0[...]111[...]0 — 3
0[...]000[...]1 — 1
Вам нужно всего лишь прочитать файл в 5 мегабайт, считывая куски по 10 кбит.
Читать нужно с каждой позиции (с 1 бита по 1024, 2 по 1025 итп), но если какой-то кусок дает уж совсем плохой результат, можно пропускать сразу K битов, где К это разница между результатом и топ10 результатом на данный момент (чтобы ничего не упустить).
На мой взгляд получится довольно быстро, хотя и совершенно не алгоритмично.
Ах, из вашего вопроса было вообще неочевидно, что вам нужны включенные биты на всех позициях по побитовому произведению выбранных последовательностей… Теперь всё ясно.
(Думая вслух.) Как вариант — просмотреть список, сосчитать, сколько раз встречается каждый бит. Просмотреть второй раз и назначит каждому элементу взвешенный рейтинг — 1 для каждого включенного бита / количество таких битов. Отсортировать по рейтингу и взять первые десять элементов. Эвристика, конечно, но вроде как логичная.
А почему отбрасываете самый очевидный способ:
Взять любое сочетание, потом по очереди примерять каждую оставшуюся последовательность, может ли она улучшить сочетание (главный параметр — увеличение площади покрытия, побочный — кол-во единичных битов).
Сложность линейная
N = 2. Просматриваем сверху; на первом и втором шаге складываем первые два элемента; на третьем видим, что если заменить первый на третий, получим плюс в 1 бит, заменяем. Но правильный ответ — взять первый и четвертый элементы.
Хотя если несколько раз просмотреть, может и выгорит чего.
N=2. На третьем шаге мы выкинем первый элемент, но опять-таки первый и четвертый оказываются лучше. И тут уже и повторный просмотр как-то не обнадеживает.
Если стартовать с «жадного» набора (полученного по Upd2), а потом локально улучшать, то можно получить еще лучшее значение. Но и здесь нет гарантии, что мы найдем оптимальный набор.
Тоже не годится. Здесь пара (1,2) сразу заменится на (1,4) — если мы будем рассматривать все возможные замены одной строки из набора (их будет N*(S-N)) и брать из них самую эффективную.
Есть пример для L=22:
0011 1111 1111 1100 0000 00
0000 0000 1111 1111 1111 00
0101 0101 0101 0101 0101 01
1010 1010 1010 1010 1010 10
Здесь «жадный» алгоритм выдаст пару (1,2) — 18 единиц, и уйти из нее уже не удастся, остальные пары кроме (3,4) дают только 17. Так что моя эвристика тоже не работает.







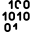 Простой
Простой
 Простой
Простой


