import pandas as pd
pd.read_csv('in.csv', sep=';', header=None) \
.drop_duplicates(4, keep='first') \
.to_csv('out.csv', header=False, index=False)from functools import lru_cache
@lru_cache(maxsize=None)
def write(unique_field):
fo.write(line)
with open('in.csv', 'r') as fi, open('out.csv', 'w') as fo:
for line in fi:
write(line.rstrip().split(';')[-1])import numpy as np
from skimage.util import view_as_windows # Библиотека scikit-image
tsize = 256
image = np.random.randint(0, 256, (8192, 8192, 3), np.uint8)
# Значения яркости - это канал L из пространства LAB
lab_l_channel = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)[..., 0]
# Плитки 256x256
tiles = view_as_windows(lab_l_channel, (tsize, tsize), (tsize, tsize))
# Примечательно, что
assert np.shares_memory(lab_l_channel, tiles) == True
# Средняя яркость в виде матрицы 32х32
lightness = tiles.reshape(-1, tsize ** 2).mean(axis=-1).reshape(np.array(image.shape[:2]) // tsize)import numpy as np
a, b, c = np.random.randint(0, 256, 3, dtype=np.uint8)
palette = [ [a, b, c], [a, a, b], [c, a, b], [b, a, c], [c, c, a] ]
rgb_img = [
[ (a+3, b-2, c-1), (a, a+1, b-2), (c+2, a, b-3) ],
[ (b, a-2, c+1), (c, c+2, a-1), (b-1, a, c-3) ],
[ (a, a+1, b-2), (a+2, b-2, c-1), (c+1, c+1, a-2) ]
]
palette = np.array(palette).reshape(1, 1, 5, 3)
rgb_img = np.array(rgb_img).reshape(3, 3, 1, 3)
indices = np.linalg.norm(palette - rgb_img, axis=-1).argmin(axis=-1).ravel()
print(indices)[0 1 2 3 4 3 1 0 4]from sklearn.cluster import KMeans
a, b, c = np.random.randint(0, 256, 3, dtype=np.uint8)
palette = [ [a, b, c], [a, a, b], [c, a, b], [b, a, c], [c, c, a] ]
rgb_img = [
[ (a+3, b-2, c-1), (a, a+1, b-2), (c+2, a, b-3) ],
[ (b, a-2, c+1), (c, c+2, a-1), (b-1, a, c-3) ],
[ (a, a+1, b-2), (a+2, b-2, c-1), (c+1, c+1, a-2) ]
]
result = (
KMeans(n_clusters=len(palette), init=np.array(palette), n_init=1)
.fit_transform(np.array(rgb_img).reshape(-1, 3))
.argmin(axis=-1)
)
Run pip install -r requirements.txt to install the necessary packages. Additionally you will need PyTorch (>=1.0.1).conda install tensorflow-gpu
messages = {
14: 'Ты ещё маленький, тебе нужно подрасти',
20: 'Ты ещё не взрослый, но уже подросток',
50: 'В меру упитанный мужчина в полном расцвете сил',
99: 'Да ты уже старик',
120: 'Тебе на кладбище давно прогулы ставят'
666: 'Столько не живут'
}
age = int(input("Введите свой возраст: "))
for age_threshold, message in messages.items():
if age <= age_threshold:
print(message)
breakfrom ast import literal_eval as eval # ast.literal_eval() безопасный, обычный eval() - нет
with open('input.txt', 'r') as fi, open('output.txt', 'w') as fo:
cache = set()
for line in fi:
title = eval(line).get('title')
if title not in cache:
cache.add(title)
fo.write(line)from ast import literal_eval as eval
from functools import lru_cache
@lru_cache(None)
def process(title):
print(record, file=fo)
with open('input.txt', 'r') as fi, open('output.txt', 'w') as fo:
for record in map(eval, fi):
process(record['title'])>>> process.cache_info()
CacheInfo(hits=994960, misses=5040, maxsize=None, currsize=5040)
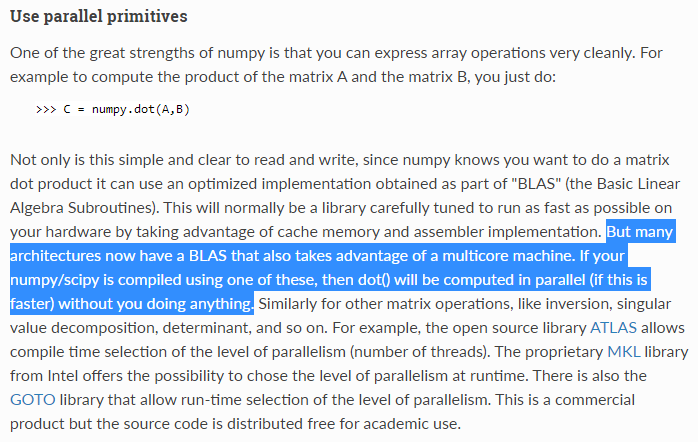
if not IsLanguageExistInWikipedia(language):
print('no results')