Python
431
Вклад в тег






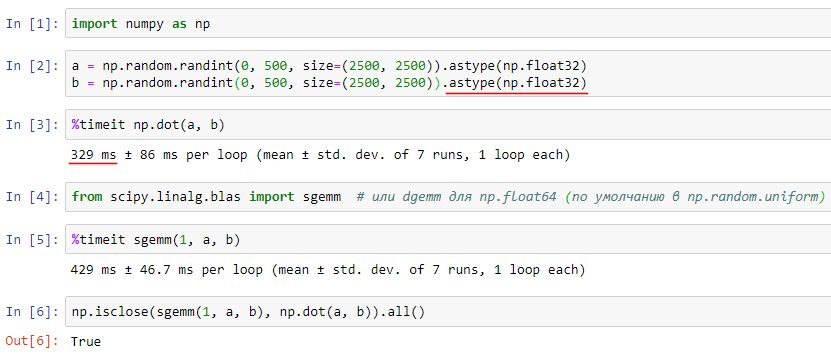
import numpy as np
from collections import deque
from itertools import combinations
# data = np.array([1487, 1847, 4817, 4871, 7481, 7841, 8147, 8741])
np.random.seed(42)
data = np.random.randint(0, 100000, 1000)
data.sort()
# Интуитивный подход (baseline), O(n^3)
def find_evenly_spaced_v1(data):
for a, b, c in combinations(data, 3):
if b - a == c - b:
yield a, b, c
# Эмпирическая оптимизация, O(n^2)
def find_evenly_spaced_v2(data):
dataset = set(data)
for a, c in combinations(data, 2):
b, mod = divmod(a + c, 2)
if (mod == 0) and (b in dataset):
yield a, b, c
# Векторный вариант
def find_evenly_spaced_v3(data):
grid = data.reshape(-1, 1) + data.reshape(1, -1)
divs, mods = np.divmod(grid, 2)
mask = np.tri(*grid.shape, -1, dtype='bool') & np.isin(divs, data) & ~ mods.astype('bool')
for c, a in zip(*np.where(mask)):
b = divs[a, c]
a, c = data[[a, c]]
yield a, b, c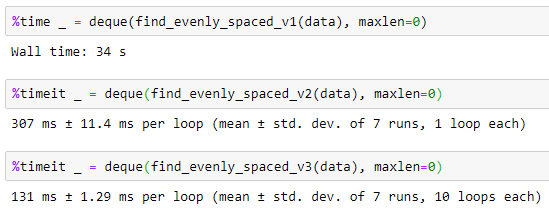
import re
def decode(encoded):
def repl(m): return m.group(2) * int(m.group(1))
reg = re.compile('\((\d+)(\w+)\)')
while True:
decoded = reg.sub(repl, encoded)
if decoded == encoded:
return decoded
encoded = decoded
assert decode('(2(3ac)a)') == 'acacacaacacaca'
assert decode('(3(2aba))') == 'abaabaabaabaabaaba'
assert decode('(3a)') == 'aaa' # уменьшение длины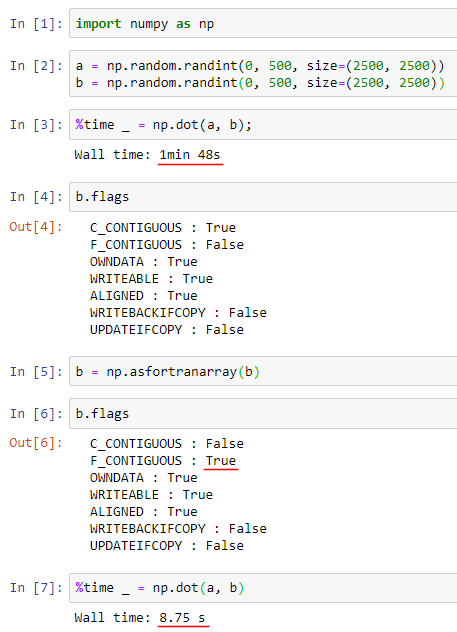
import cv2
import numpy as np
data = """1 -9 -2 8 6 1
8 -1 -11 -7 6 4
10 12 -1 -9 -12 14
8 10 -3 -5 17 8
6 4 10 -13 -16 19"""
# matrix = np.random.randint(-128, 128, (1000, 1000), dtype=np.int32)
matrix = np.int32([line.split() for line in data.splitlines()])
def find_max_kernel(matrix, border=cv2.BORDER_ISOLATED):
max_area = 0
mask = np.float32(matrix < 0)
ones = np.ones_like(mask)
conv_x = np.zeros_like(mask)
conv_y = np.zeros_like(mask)
max_h, max_w = mask.shape
for h in range(1, max_h + 1):
cv2.filter2D(mask, -1, ones[:h, None, 0], conv_y, (0, 0), 0, border)
for w in range(1, max_w + 1):
area = h * w
if area > max_area:
cv2.filter2D(conv_y, -1, ones[None, 0, :w], conv_x, (0, 0), 0, border)
if conv_x.max() == area:
max_area, shape = area, (h, w)
else:
if w == 1:
max_h = h - 1
if h == 1:
max_w = w - 1
break
if h >= max_h:
break
cv2.filter2D(mask, -1, np.ones(shape, np.float32), conv_x, (0, 0), 0, border)
p1 = np.array(np.unravel_index(conv_x.argmax(), conv_x.shape))
p2 = p1 + shape - 1
return p1, p2
print(*find_max_kernel(matrix), sep='\n')