здравствуйте! помогите пожалуйста
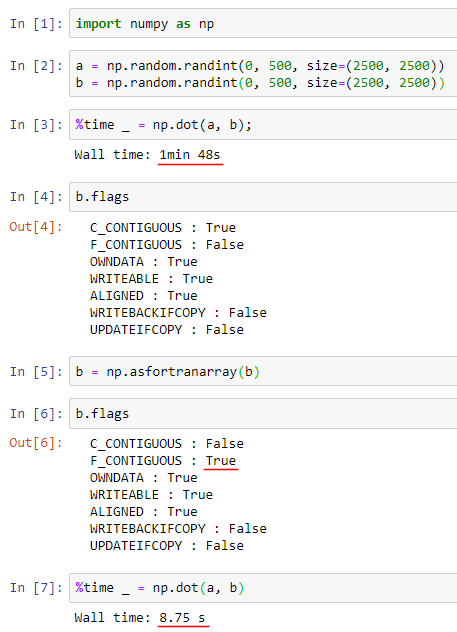
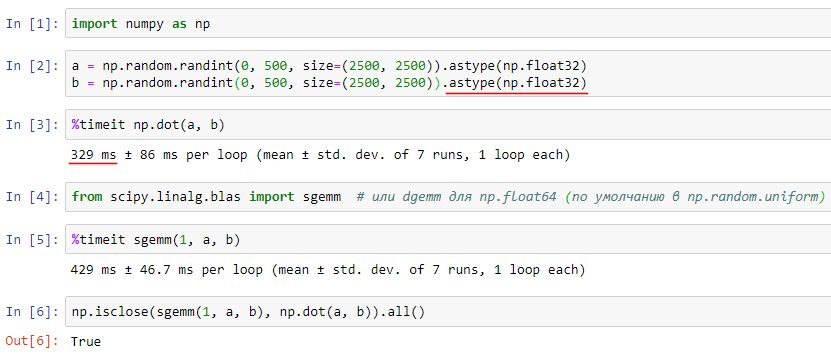
У меня есть 2 матрицы размером 2500*2500, заполненные с случными числами от 0 до 500. Сначала матрицы A и B разделяю на подматрицы с помощью numpy.array_slit. Потом умножаю подматрицы с помощью dot в одном потоке. Eсли так сделать, то уходит много времени.
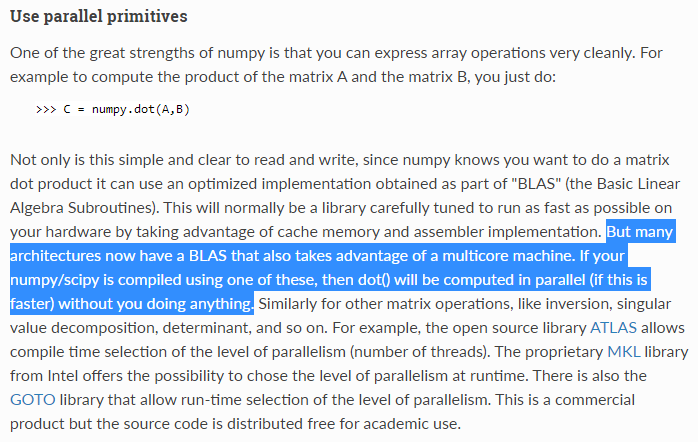
Хочу сделать умножение подматриц в отдельных потоках. То есть например мартрицу А разделяю на две части на a1 и a2. Также B матрицу разделяю на b1 и b1. Хочу в tread1 умножить a1 и b1, в tread2 умножить a2 и b2. Как это реализовать? Какой нибудь метод есть в numpy, что отдельно умножить подматрицы?
вот код:
import threading
import numpy as np
import timeit
import time
thread_lock = threading.Lock()
class MyThread(threading.Thread):
def __init__(self, name, delay, a, b):
threading.Thread.__init__(self)
self.name = name
self.delay = delay
self.a= a
self.b = b
def run(self):
print('Starting thread %s.' % self.name)
thread_lock.acquire()
matrix_multiplctn(self.a,self.b, self.delay)
thread_lock.release()
print('Finished thread %s.' % self.name )
def matrix_multiplctn(a, b, delay):
a1=np.array_split(a, 2, axis=1) #разделяю по столбцам
b1=np.array_split(b, 2, axis=0) #разделяю по строкам
start_time = timeit.default_timer()
c = np.dot(a1,b1)
print(timeit.default_timer() - start_time)
time.sleep(delay)
print(c)
a=np.random.randint(0,500, size=(2500,2500))
b=np.random.randint(0,500, size=(2500,2500))
thread = MyThread("A", 0.1, a, b)
start_time1 = timeit.default_timer()
thread.start()
thread.join()
print("Время выполнения A: ", timeit.default_timer() - start_time1)
print('Finished.')