

Что выбрать Python(Django) или PHP(Laravel/Yii)?
Есть ли способ связать базу товаров для сайтов?В целом, способов довольно много, но я не думаю, что существует готовое решение уровня "Модуль Modx, "поставил и забыл".
Какие есть еще варианты? Какой выбрать?Ещё есть варианты, типа Redis/Memcached, таблицы в памяти, вариант отключить синхронизацию с файловой системой в БД, использовать MongoDb или другую базу подобного плана и т.д., есть специальный тип таблиц, например, ARCHIVE в MySQL оптимизированные специально на запись... Масса вариантов, в общей сложности.
Шлем запрос на api, который ничего не делает. Потом грепаем логи по крону.Не уверен, что это быстрее чем база данных.
Шлем запрос на api, там скрипт делает INSERT в базу - инсерт в базу скорее всего будет медленный, нафиг.Если Вам нужен счётчик, это будет не "INSERT" а скорее "UPSERT" ("INSERT or UPDATE"), а ещё лучше сразу UPDATE (т.е. заводить запись с текущей циферкой счётчика до того, как будет пытаться её UPDATE'ить).
Шлем запрос на api, там простой скрипт делает append в файл. По крону считаем что там записалось - выглядит уже лучше.А как на счёт конкурентного доступа к файлу?
Есть ли смысл в 2017 году изучать другие системы контроля версий такие как Mercurial или Subversion?Есть, но в процентном соотношений этот "смысл" будет довольно скромным. Кстати, помимо Git, Mercurial и Subversion, есть ещё и другие системы...
очень часто вижу такое мнение что построение сеток на основе "float" или "inline-block" лучше, потому что флексы поддерживаются не всеми браузерами. Так ли это и почему в таком случае они так популярны?Это действительно так. Но я Вам больше скажу, даже CSS как таковой (или HTML-5), поддерживается не всеми браузерами (IE-1 насколько я помню, CSS не поддерживал). Но я не думаю, что это повод отказаться от CSS или HTML5. И вообще, само по себе выражение "не всеми браузерами" - довольно размытое, что-то из области "не все продукты одинаково полезны".
и почему в таком случае они так популярны?По тому, что они дают довольно большую гибкость, сокращают количество "случайностей" (неожиданного поведения элементов), такой код в целом более читаемый, чем "простыни" из float'ов, и так далее...
Это я привел всего лишь пример, вопрос не про него, а про ситуацию вообщеЕсли это не социальная сеть, где трафик исчисляется петабайтами, а нагрузка на базу - тысячами запросов в секунду, то наиболее рациональное решение в подобных вопросах, на мой взгляд, давно было найдено и называется оно ООП, в т.ч. для обработки данных, во многих системах (например, фреймворках) присутствует такая сущность как объект (или "модель" если угодно), в которую Вы без особого труда можете добавить новое свойство, рассчитываемое динамически. Это отлично работает в большинстве случаев.
Как понять какие части кода надо делать универсальные а какие жеско прописывать?
Интересует сайдбар, и контентная часть ..Что именно Вас интересует?
интересно может ли робот проиндексировать html, ведь по ссылкам попасть туда он не можетЕсли Вы где-то не прописывали ссылку на этот файл, например, в sitemap.xml, вряд ли какой-то поисковик будет тратить свои ресурсы, в поисках файлов, которых теоретически на сервере нет. По этому, с вероятностью 99% можно сказать, что проиндексирован он не будет (даже если поисковик, каким-то чудесным образом узнал бы о том, что есть такой файл как "index.html", вряд ли бы он стал его индексировать исходя из тех соображений, что пользователь по ссылкам всё равно не сможет туда попасть).
Как встроить gitlab в phpstorm?В каком смысле "встроить"? Вы можете на GitLab'e создать проект/репозиторий, получить его ссылку и делать pull/push/etc Вашего местного (локального) git-репозитория с проектом в удаленный репозиторий, лежащий на GitLab'е.

'strict' => true, (в "разделе" 'mysql'), значение поменять на false.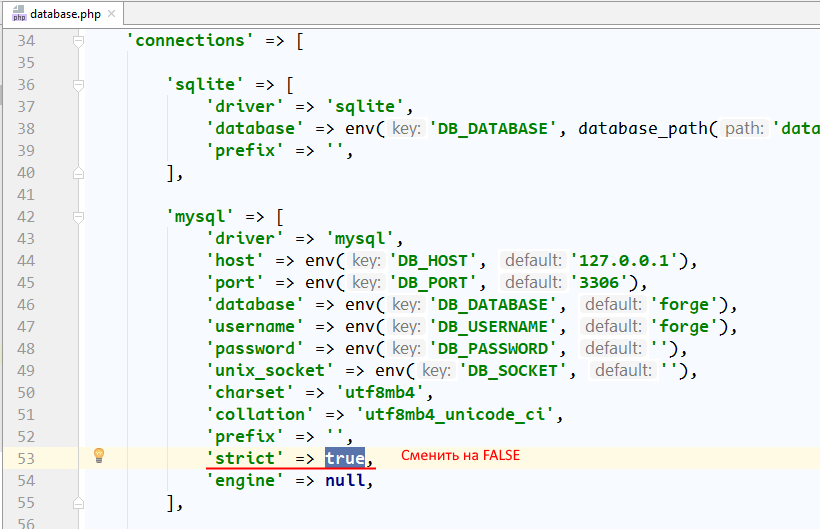
tab1[field1]
Так как быть?Определиться с тем, являются ли картинки часть исходного кода или всё же частью внешних/временных данных? Если частью исходного кода (например, логотип из макета сайта) - сохранять, если просто какие-то временные данные - выдавайте их отдельно всем желающим.
Допустим использование симки в модеме и трафик с торентов можно отследить. Как можно отследить раздачу трафика по wi-fi провайдеру?Самый просто способ (проверку TTL) уже описал предыдущий оратор, не буду повторяться :)
как вывести значение joxi.ru/eAO7G6NUxo7q0A?Например так:
<?php
$json = '{"p":{"o":{"uh":1}},"c":[{"p":""},{"p":""},{"p":""}],"h":[{"c":"Тариф"},{"c":"Скорость"},{"c":"Стоимость"}],"b":[[{"c":"Link 1"},{"c":"1 Мбит/сек"},{"c":"390 руб/мес"}],[{"c":"Link 4"},{"c":"4 Мбит/сек"},{"c":"590 руб/мес"}],[{"c":"Link 8"},{"c":"8 Мбит/сек"},{"c":"690 руб/мес"}],[{"c":"Link 20"},{"c":"20 Мбит/сек"},{"c":"790 руб/мес"}],[{"c":"Link MAX"},{"c":"До 120 Мбит/сек"},{"c":"1000 руб/мес"}]]}';
$data = json_decode($json);
var_dump($data->h[0]->c);Какую базу данных выбрать ? Подойдет ли MySQL для этих задач?При наличии должного опыта работы с ней, навыков правильного проектирования БД и полного понимания, зачем делать "именно так" и "почему не иначе?", думаю вполне подойдёт. А вообще, обычно базы оценивают не количеством записей в 1-ой (одной) таблице, а общим объёмом данных (в гига/пета- байтах) и некоторыми другими параметрами.
- поиск - есть ли запись в базе данных с указанным названием, если есть то обновляем данные там. Т.е. перед тем как добавить запись (а их напомню - вначале будет 5-40 млн и будут постоянно возрастать) будет проверять есть она в базе данных и добавлять/обновлять данные.Для этого есть индексы, во всех известных мне базах. Предположительно - стандартный B-tree индекс, работает он во всех базах примерно одинаково.
На базу данных будут примерно такие нагрузки:Нагрузки у Вас будут на железо а не на базу, если оно выдержит - то с точки зрения БД - логических проблем для хранения 40млн. записей - я не вижу.
Хочу узнать какими способами можно организовать структуру хранения большой информации ?"Большой инфомрации" или больших объёмов данных? 40млн. записей - это совершенно не обязательно большой объём. Например индекс по числовому (INT) полю для 40млн. записей будет занимать всего несколько мегабайт. Для хранения именно "большой информации" - можете взять, например, PostgreSQL, там есть готовый механизм, TOAST, предназначенный специально для этого, или спроектировать базу MySQL таким образом, что бы нужные данные лежали отдельно от всякого "информационного мусора" ("хвостов"), это позволит сократить размер отдельной таблицы на диске и как следствие - повысить скорость работы с ней.