Мне нужно решить аналог многокритериальной задачи о назначениях, но есть ключевая деталь - на "должность" могут быть назначены несколько человек.
По сути - есть субъекты Zi; есть параметры, по которым они оцениваются - Yi. И есть нечёткие значения - низкая совместимость, средняя, и высокая - это Xi, но на деле их пять. Для каждого субъекта нужно определить уровень совместимости по Yi критериям.
Очень похоже на то, что есть в
этой статье, но по итогу значения получаются неудовлетворительными.
Покажу в картинках. Вот наборы значений:
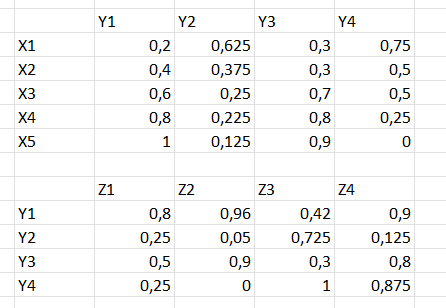
Вот (min-max)-композиция:
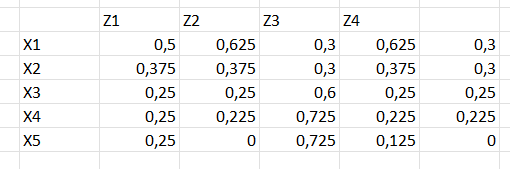
Вот (max-prod)-композиция:
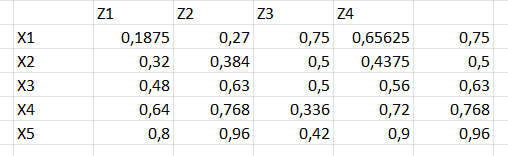
И в итоге результаты примерно схожие, но неудовлетворяющие. Что-то вечно не так с Z4 - 0,875 по Y4 - это очень плохой результат, а если я меняю Y3 на 0 - что тоже очень плохо - ничего не меняется.
Мне нужно получить результат наподобие: Z1 - X4, Z2 - X5, Z3 - X1, Z4 - X2, но это просто пример.
Также я пробовал сделать что-то по этой
статье, результат хороший, но я слабо понимаю алгоритм в конце и не уверен, что правильно интерпретирую данные. Имеет ли вообще смысл использовать его для моих данных?
В целом - может есть какие-то другие рекомендации по многокритериальной задаче о назначениях? Я смотрел англоязычные источники, но там полно платных статей, да и я не вижу пользы искать где-то к ним доступ, если не знать, что ищешь.

