
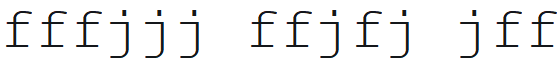 https://wdho.ru/856776 Вот эту фотку он считывает как: fffj434 ffjfji jf
https://wdho.ru/856776 Вот эту фотку он считывает как: fffj434 ffjfji jf 
fffjjj ....
Простой
Простой
 Простой
Простой
Простой
Простой
 Простой
Сложный
Простой
Сложный






