Делаю web scrapping c Сoinmarketcap. Хотел прочитать информаци по криптовалюте Solana и UnitTest не проходит тк не получается взять текст из HTML тега и прочитать слово Solana Price потому-что у меня весь HTML doc какая-то кракозябра. Пытался подобрать кодировку с помощью online encoders не получилось. Пару раз приходил нормальный результат, но я не сделал скриншот к сожалению пока воспроизвести не получилось. У сайта есть какая-то защита если да то как ее обойти?
URL ресурса:
https://coinmarketcap.com/currencies/solana/
Метод читающий (web scrapping) с ресурса
public async Task<string> ReadTextFromAsync(string source)
{
if (string.IsNullOrWhiteSpace(source))
return string.Empty;
var sb = new StringBuilder();
var web = new HtmlWeb();
var HTMLdoc = await web.LoadFromWebAsync(source, Encoding.UTF8);
HTMLdoc.DocumentNode
.DescendantsAndSelf()
.ToList()
.ForEach(node =>
{
// Only if HTML node is type Text
if (node.NodeType == HtmlNodeType.Text)
// Only if HTML node contains text and isn't empty
if (!string.IsNullOrWhiteSpace(node.InnerText))
// Take only text from node
sb.AppendLine(node.InnerText.Trim());
});
return sb.ToString();
}
Скриншот полученного текста:
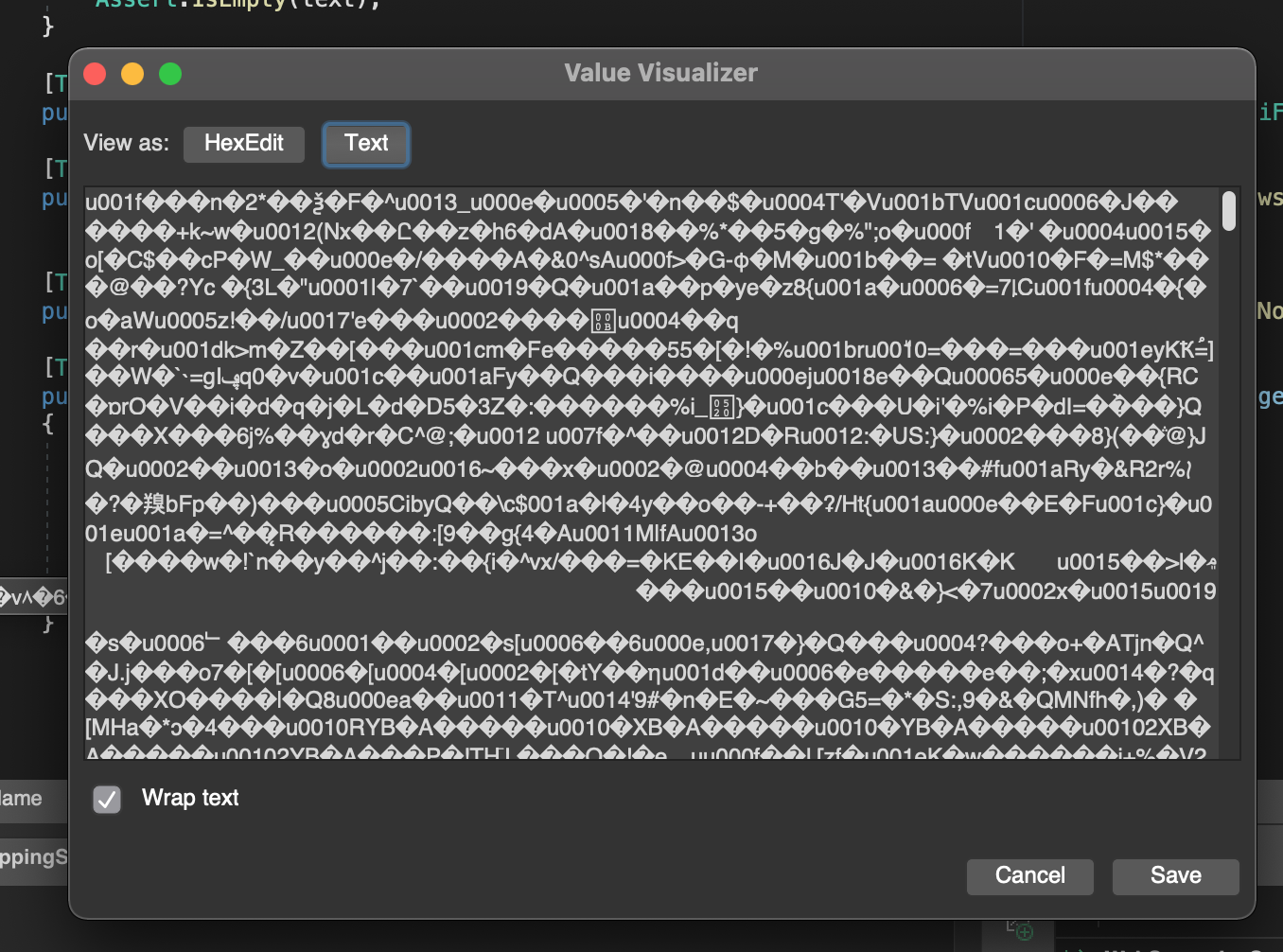
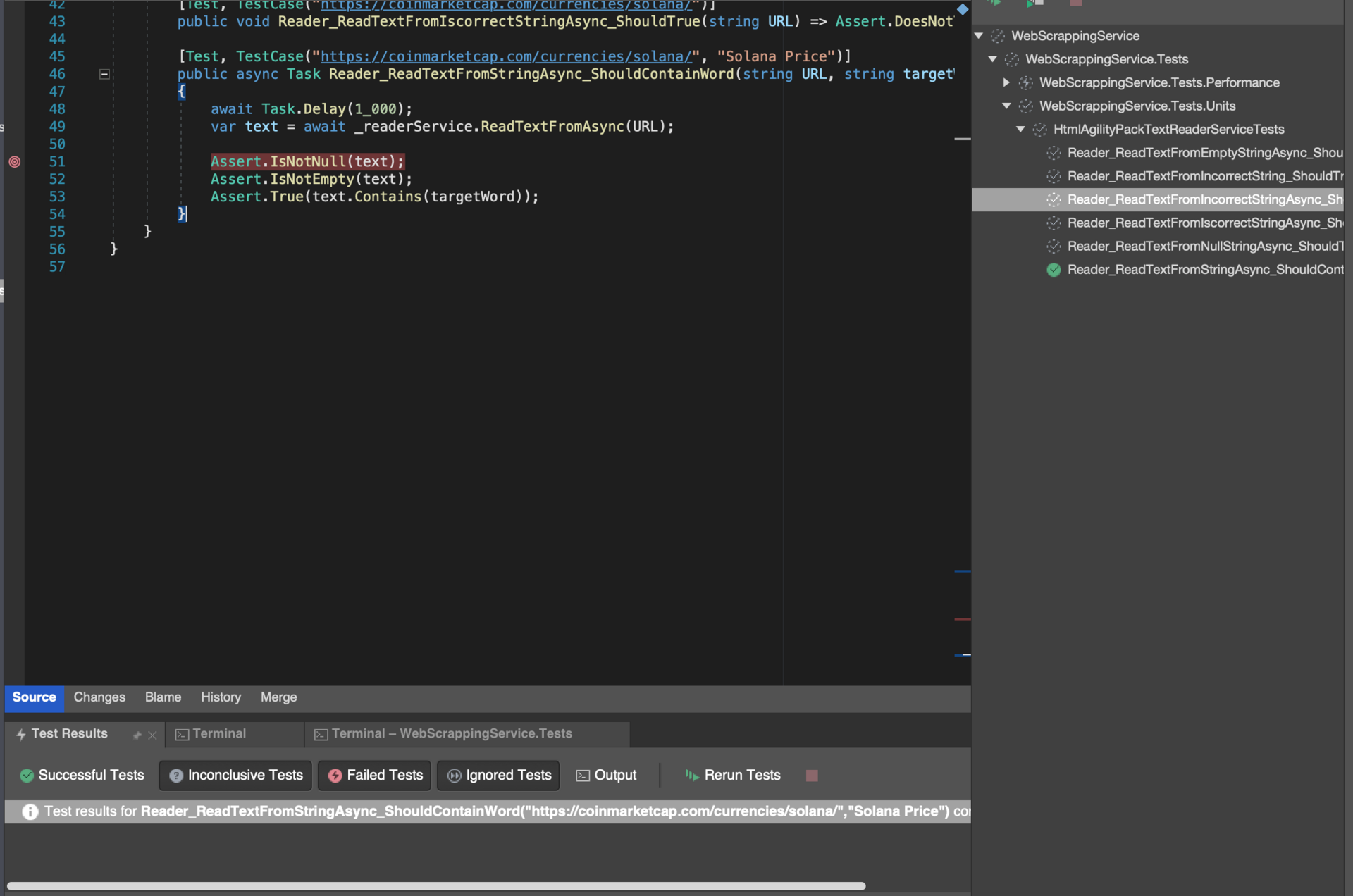
Спустя какое-то время (долго) получилось воспроизвести результат и тест прошел. Можно ли как-то обойти эту проблему?
Скриншот прошедшего теста:

 Средний
Средний
 Средний
Средний





