Низзя так.
Вы поступаете как поступали бы с реляционной СУБД типа MySQL и т.п.
Там связи между таблицами - это норма.
А Mongo их очень плохо обрабатывает.
В ней делают
денормализацию.
Тут я присоединяюсь к
grinat
Если уж вы методами предназначенными для реляционных СУБД работаете, то:
Правильно будет удалить mongo и поставить mysql/posgres
UPDATED:
qovalenko,
Я Вас понимаю, дело в том, что если добавить данные второй коллекции к данным первой, то при обновлении этих данных нужно будет изменять их в нескольких документах первой коллекции, а это не так уже и удобно.
Это нормально.
Это следствие
денормализации.
Это такая плата за плюсы Mongo.
Если хотите пользоваться
нормальной формой, без дублей - то вам прямой путь к реляционным СУБД: PostgreSQL/MySQL/MS-SQL/Oracle и т.п.
Ведь NoSQL не просто так быстры и не просто так хорошо масштабируются.
Неужели вы думаете, что разработчики реляционных СУБД более 40 лет их создают и не могут добиться таких впечатляющих результатов, как за смешные 10 лет достигли NoSQL?
В Mongo и прочих NoSQL много чего урезанно по сравнению со строгими СУБД каковыми являются реляционными. И только это и позволяет им работать быстро и масштабироваться просто.
Но за все нужно платить.
Ну например, чего только стоит, что данные на серверах Mongo при репликации станут верными "когда-нибудь потом, но когда точно мы не знаем"
Согласованные в конечном счете (Eventually Consistent)
Или же упомянутая вами проблема с тем, что необходимо отслеживать дубли при денормализации.
Я вам больше скажу - если вы не хотите чтобы производительность вашей системы проседала - то эти дубли вам придется устранять не сразу при изменении, а какой-то отдельной процедурой синхронизации, запускаемой, к примеру, раз в час. А в течении этого часа в одном части вашей Mongo будут одни данные, а в другой части - другие данные.
То, как вы хотите сделать - с нормализаций - в Mongo делать нельзя из соображений производительности и корректности работы транзакций.
Ну не предназначена она для этого.
Именно это в Mongo и вырезано (точнее изначально не реализовано) по сравнению с реляционными СУБД.
Только в реляционных СУБД как раз всё можно сделать именно так, как вы и хотите (но там вы заплатите ограничениями при масштабировании).
Если проект не очень большой (скажем так: размеры данных на несколько терабайтов или меньше, что позволяет использовать 1 сервер для всех данных; и максимальное число серверов при репликации 2-3) - тогда реляционные СУБД будут весьма производительны и смысла в Mongo нет.
Вот здесь на видео все доходчиво объяснено - где у кого какие преимущества и какие недостатки:
Postgres vs Mongo / Олег Бартунов
Если же вам нравится Mongo, потому что она schemaless, то подобное уже есть и в PostgreSQL
"Умное" индексирование jsonb | Олег Бартунов, Ники...
Отныне вам необязательно все поля прописывать отдельно в CREATE TABLE (но желательно все же отдельно прописывать, через которые осуществляются связи между таблицами - то есть всяческие ID - чтобы оптимизатор запросов лучше работал)
Внимание, для этого в PostgreSQL используется тип данных JSONB, не путать с просто JSON
Если же вы хотите оставаться с Mongo, то делать нужно так, чтобы 1 запрос пользователя в вашем интернет-магазине (или что там у вас) в конечном итоге сводился к 1 запросу на извлечение данных из одной-единственной коллекции Mongo.
А это значит, что будет нужна денормализация, которая и означает дублирование данных. Что ведет к необходимости синхронизации дублей.
При этом, если изменение данных интенсивное, то синхронизацию дублей придется делать отложенную (по cron и т.п.), а не сразу в момент записи.
Это нормально в Mongo. Разработчики Mongo сами так и рекомендуют делать.




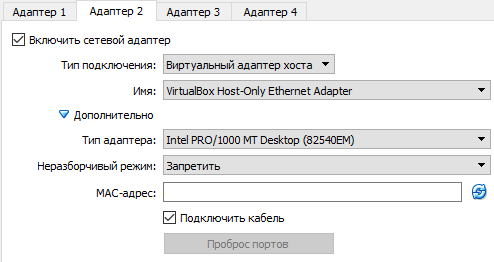
 3) Сменил настройки IP в адаптере хоста на:
3) Сменил настройки IP в адаптере хоста на: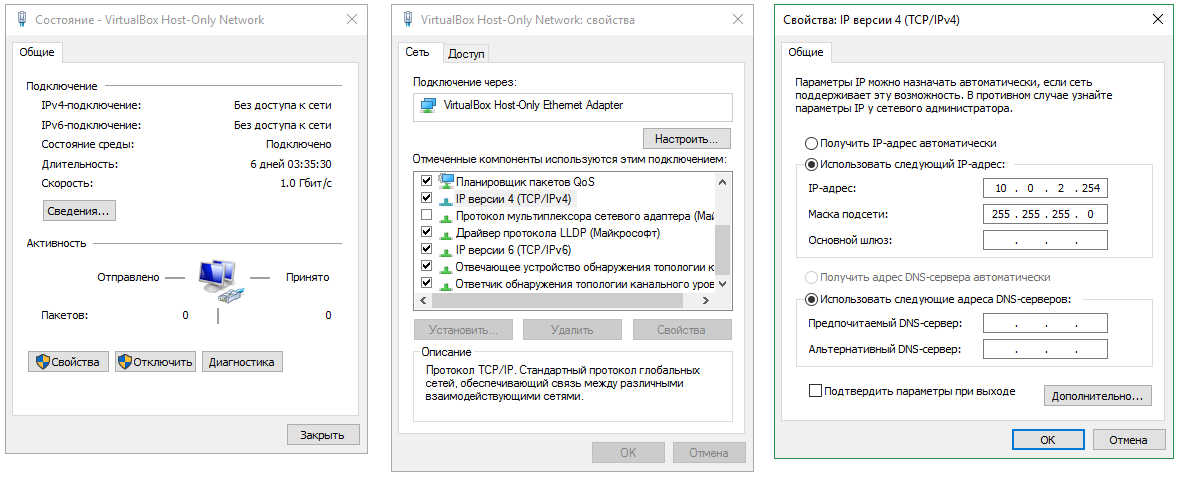
 4) Включил машину.
4) Включил машину.






