Алан Гибизов, вы оказались правы.
Нашёл байт 0xf6 и 3 байта, следующие за ним:
f6 77 2c 0d = 11110110 01110111 00101100 00001101
Видно, что эта последовательность не валидна для utf-8. b'\xf6\x77\x2c\x0d'.decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf6 in position 0: invalid start byte
Оказалось, что файл закодирован кодировкой latin-1 (она же iso-8859-1): b'\xf6\x77\x2c\x0d'.decode('latin-1')
'öw,\r'
Последовав вашему совету, нашёл байт 0xf6 и 3 байта, следующие за ним:
f6 77 2c 0d = 11110110 01110111 00101100 00001101
Видно, что эта последовательность не валидна для utf-8. b'\xf6\x77\x2c\x0d'.decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf6 in position 0: invalid start byte
Оказалось, что файл закодирован кодировкой latin-1 (она же iso-8859-1): b'\xf6\x77\x2c\x0d'.decode('latin-1')
'öw,\r'
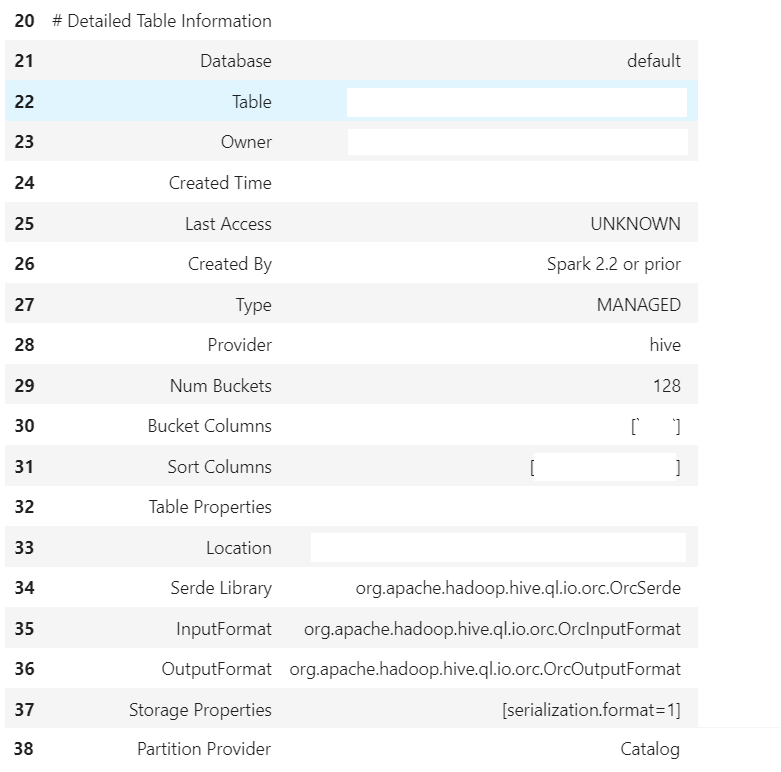
Данные поступают нам ежедневно батчами. Соответственно, ежедневно запускается код, отрабатывающий Data Quality. Результаты работы этого кода складываются в какую-то БД. Затем, на данных из этой БД мы можем построить разные таблички или нарисовать разные графики.
Так вот, вопрос как раз про схему такой БД.
Saboteur, я чего-то не понимаю. Каким образом я могу сделать запись в таблицу Phone_1 без ссылки на существующую запись в таблице Employee? Поле employee_id же является внешним ключом и при этом NOT NULL.
Saboteur, почему нет никакой привязки? Есть же внешний ключ Employee_id NOT NULL (пунктирная линия). И этот внешний ключ помешает вам сгенерить любую запись.