для дальнейшей работы в python.ну да обычно такое и делается через "рекурсивный CTE", решение можно погуглить, там стандартный шаблон, если для тебя это сложно, есть еще часто используемое решение на уровня ЯП, который это обрабатывает, у тебя питон, выгружаешь одним запросом свое "дерево" в плоском виде, а на питоне уже собираешь в нужную структуру.
(
df
.assign(
groups=(df['EventType'] != df['EventType'].shift())
.cumsum()
)
.groupby('groups'
)
.agg(
first= pd.NamedAgg(column='EventTime',aggfunc=lambda x: np.min(x)),
last= pd.NamedAgg(column='EventTime',aggfunc=lambda x: np.max(x)),
EventType= pd.NamedAgg(column='EventType',aggfunc=lambda x: set(x).pop()),
user_id=pd.NamedAgg(column='user_id',aggfunc=lambda x: set(x).pop()),
)
.reset_index(drop=True)
.loc[:,['user_id','EventType','first','last']]
)(
df
.groupby(
(df["EventType"] != df["EventType"].shift())
.cumsum()
)
.agg({"EventTime" : ["min", "max"]})
)(
df.assign(
EventTime=lambda x: pd.to_datetime(x['EventTime'],format='%Y-%m-%d %H:%M:%S')
)
...
)


А можно ли использовать отдельную табличку на hdfs для этих целей?
На hdfs есть табличка (обычно дергаю из неё данные в hive).

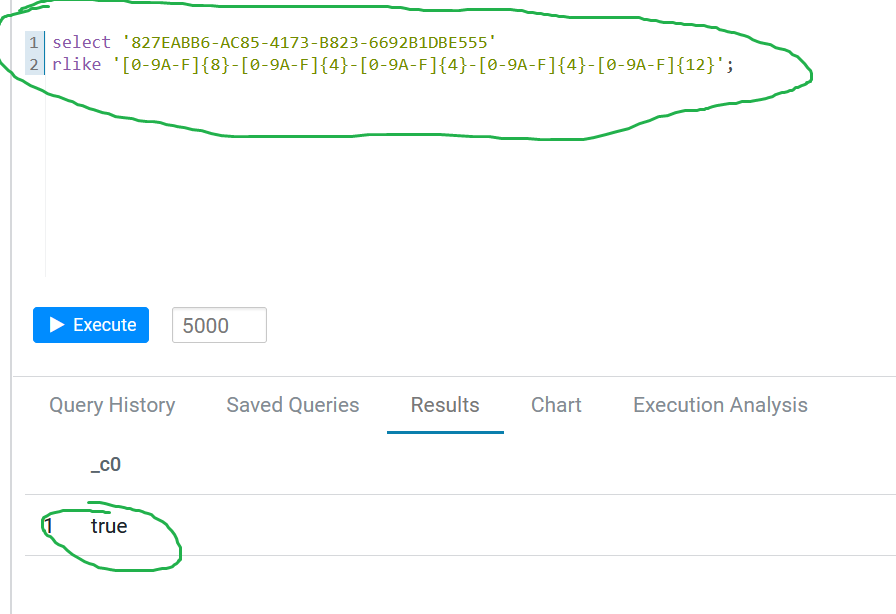
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf6 in position 3539: invalid start byte11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
SELECT
*,
FIRST_VALUE(CASE WHEN banner_id IN (13,14,15,17)
THEN banner_id
END) OVER (PARTITION BY id
ORDER BY CASE WHEN banner_id IN (13,14,15,17)
THEN banner_id
END DESC NULLS LAST) max_banner_id_1,
FIRST_VALUE(CASE WHEN banner_id IN (4,177,178)
THEN banner_id
END) OVER (PARTITION BY id
ORDER BY CASE WHEN banner_id IN (4,177,178)
THEN banner_id
END DESC NULLS LAST) max_banner_id_2
FROM test
ORDER BY banner_id
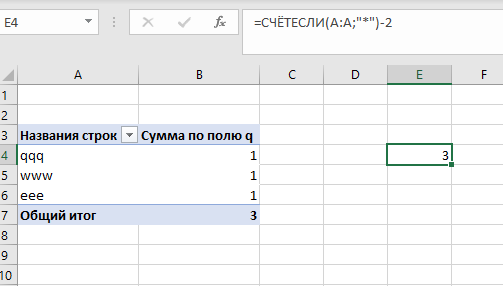
=СЧЁТЕСЛИ(A:A;"*")-2