

unread_count каждого диалога, узнать, есть ли непрочитанные сообщения: https://docs.telethon.dev/en/stable/modules/custom...
for good_name, good_id in goods.items():
goodss = store[good_id]
total_quantity = sum(i["quantity"] for i in goodss)
total_price = sum(i["quantity"] * i["price"] for i in goodss)
print(f"{good_name} - {total_quantity} штук, стоимость {total_price} рублей")app.mount("/sql_app", StaticFiles(directory=base_dir+"/static"), name="sql_app")os.path.join():app.mount("/sql_app", StaticFiles(directory=os.path.join(base_dir, "/static")), name="sql_app")main.py, не указывая директорию с проектом (base_dir). Достаточно указать directory="static":app.mount("/sql_app", StaticFiles(directory="static"), name="sql_app")parse_mode и использовать entities для вставки своей ссылки в конец сообщения как MessageEntity с типом "text_link", например, так:@dp.channel_post()
async def redactor(message: types.Message):
ent = message.entities
new_ent = [e for e in ent if e.type != "text_link"]
new_text = f'{message.text}\n'
link_text = "text for link"
link_address = "http://t.me/some_link"
new_ent.append(types.MessageEntity(
type="text_link", offset=len(new_text),
length=len(link_text), url=link_address
))
new_text = f'{new_text}{link_text}'
await message.edit_text(new_text, entities=new_ent)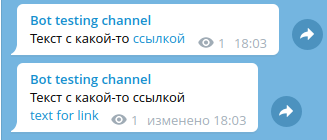
...
for member in guild.members:#цикл, обрабатывающий список участников
cursor.execute(f"SELECT id FROM users where id={member.id}")#проверка, существует ли участник в БД
if cursor.fetchone()==None:#Если не существует
...yt-dlp --version
or меньший приоритет, чем у оператора ==. Сначала выполняется message.text == 'BLA', затем 'BLABLA' — последнее всегда расценивается как True (непустая строка). Можно расставить скобки для лучшего понимания приоритета выполнения:if (message.text == 'BLA') or 'BLABLA':True:if (message.text == 'BLA') or True:True.if message.text == 'BLA' or message.text == 'BLABLA':in:if message.text in ('BLA', 'BLABLA'):
markup = types.ReplyKeyboardMarkup(resize_keyboard=True)
if len(list1) == 1:
markup.row(list1[0])
if len(list1) == 2:
markup.row(list1[0], list1[1])
if len(list1) == 3:
markup.row(list1[0], list1[1], list1[2])markup = types.ReplyKeyboardMarkup(resize_keyboard=True)
markup.row(*list1)* в Python можете прочитать здесь.
def text_size(text: str, encoding: str = 'utf-8') -> int:
return len(text.encode(encoding))page.evaluate нужно передавать JavaScript-функцию или выражение. В Python-версии этот метод принимает строку с JS-кодом: https://miyakogi.github.io/pyppeteer/reference.htm...page.evaluate((query), "console.log(query)", query)await page.evaluate(f'console.log("{query}")')
SELECT с нужным chat_id, и уже в коде Python проверяйте, какое значение у поля verification — не обязательно это делать средствами SQL.
json_encode). Но в Python-версии вы просто преобразуете словарь в строку (str(data).encode()), в результате чего получаете не JSON, а строковое представление (representation) словаря. Вам следует использовать модуль json для кодирования словаря в JSON:import hashlib
import hmac
import json
secret_key = "6cc765db400218ab83394f4f3c8e00866b05a0vq"
data = {
'orderId': '6555214',
'shopId': '4d499d82-2b99-4a7e-be26-5742c41e69e7'
}
signature = hmac.new(secret_key.encode(), json.dumps(data).encode(), hashlib.sha256).hexdigest()
data['signature'] = signaturejson.encode нужно указать, какие использовать разделители (без пробелов):signature = hmac.new(secret_key.encode(), json.dumps(data, separators=(',', ':')).encode(), hashlib.sha256).hexdigest()