На вопросы:
>>что нужно сделать в первую очередь придя на рабочее место
и
>>как составлять документацию к проекту
вам должен ответить ваш руководитель, а не интернет-сообщество.
Если у вас нет руководителя (так бывает только если вы ген. директор) или вы сам являетесь руководителем вам необходимо обратиться к вышестоящему руководителю с этими вопросами.
В самом первом моем сообщении у меня не было желания посмеяться над вами и уж тем более раздуть ЧСВ (перед кем его тут раздувать-то?), мне скорее показалась нелепой та ситуация, в которой вы оказались, и мой сарказм был направлен исключительно на нашу российскую действительность, которая допускает такие ситуации, а не на вас лично.
Из всех ваших вопросов относительно адекватным является вопрос N3.
>> 3. Чем вообще занимаются программисты в самом начале работы с чужим проектом.
В первую очередь нужно найти пользователей этого продукта и спросить у них, как этот продукт работает, какие задачи он решает, как они им пользуются, попросить показать примеры работы с программой. И когда вы поймете программу с точки зрения пользователя, тогда уже можно лезть в код. А лезть в код, не понимая про что это и зачем это вообще нужно, можно даже и не пытаться.
Спасибо за советы! Планирую попробовать с 2-мя обычными роутерами, но вероятно все-таки придется "сколхозить" самодельные направленные антенны, т.к. не верю, что с обычными на 300 м пробьёт (попробую конечно). Подключить направленные антенны к роутерам планирую обычным коаксиальным кабелем, насколько я понимаю у него малое затухание, так что длина кабеля до антенны не должна иметь большого значения.
Ну я так понимаю в любом случае нужно 4 роутера и один из них д.б. с направленной антенной, чтобы "пулять сигнал", а может и два (на прием и передачу).
При этом у данного проца производительность на уровне Athlon XP 1600 (если кто-то еще помнит эти легендарные утюги). Для такой производительности я считаю TDP 27W очень низким.
Не всегда в файле хранятся именно какие-то «записи». Иногда это довольно сложные структуры бинарных данных. Последние два самодельных формата, с которыми я работал — это файл специализированного полнотекстового индекса сотен тысяч документов (да, там нужна сверхэффективность) и файлы хранения дифференциальной/инкрементной истории изменений документов (примерно то, что хранит SVN или Git у себя на сервере). Объектного представления данных из этих файлов как бы и нет, при работе используются относительно низкоуровневые алгоритмы.
Тут написано, что SQL Server память всегда забирает себе по максимуму, а отдает системе только при необходимости, когда не хватает другим процессам. Что интересно, у меня max server memory было выставлено в 3 ГБ, видимо к Virtual Size данная цифра не относится.
Если верить этой дискуссии, то Virtual Size включает в себя объем отображаемых в память файлов. Т.к. импорт данных в SQL происходил через BULK INSERT, у меня есть предположение, что SQL Server использует именно отображение файлов в память, но вот почему он не отдает это пространство?..
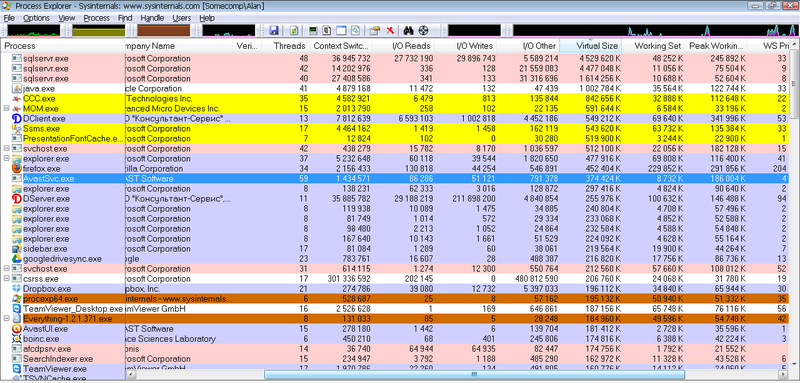
Вот что мне удалось отследить Process Explorer'ом:
Видно, что у sqrservr.exe Virtual Size имеет неприлично большой размер. Осталось разобраться, что это за Virtual Size такой и как с ним бороться. Складывается впечатление, что SQL Server выгрузил кучу своей памяти в своп.
Т.к. никакие приложения не запускались и не закрывались, то я подозреваю, что память сожрал SQL Server, т.к. на нем была основная нагрузка в ходе импорта (импортировалось около 20 ГБ данных из мелких файлов). Но непонятно, почему сейчас, когда уже никакие запросы не выполняются, эта память не освобождается и (что особенно меня беспокоит) не показывается ни в мониторе ресурсов, ни в диспетчере задач. Где же она, вот в чем вопрос?
Скриншот вот такой:
Из проверенных планшетов можно попробовать 7" IconBit NETTAB Matrix.
Из непроверенных (чисто по отзывам) — 7" Samsung Galaxy Tab 2 7.0 P3100, 8.4" Rolsen RTB 8.4 Joy, Beholder BeTab 7071 8Гб 3G (правда он не IPS, но зато с 3G :) ), Huawei MediaPad (это уже > 10 т.р.)
Спасибо за информацию! Что-то мне подсказывает, что несколькими строками кода тут не обойдешься — нужно искать описание, как именно вычисляется поблочный хэш и хэш всего торрента (т.е. хэш от группы файлов) + разбирать формат самого .torrent-файла. Странно, что подобный функционал еще не встроили ни в один торрент-клиент
При наличии трех отдельных индексов по comment_id, post_id, user_id эта таблица может содержать десятки, и сотни миллионов записей и ничего тормозить не будет. Партиционирование (разбиение данной таблицы на несколько таблиц по какому-либо критерию — например, по 10 миллионов id) применяется как правило в тех случаях, когда старые (архивные) данные изменяются очень редко, а новые (последние) очень часто. Партиционирование можно выполнить конечно и вручную (создать отдельные таблицы и работать с ними), но проще реализовать это средствами современных СУБД, поддерживающих партиционирование. Однако повторюсь, ИМХО, в вашей задаче разбивать таблицу на партиции не требуется — просто создайте необходимые индексы.
Написано
Войдите на сайт
Чтобы задать вопрос и получить на него квалифицированный ответ.

>>что нужно сделать в первую очередь придя на рабочее место
и
>>как составлять документацию к проекту
вам должен ответить ваш руководитель, а не интернет-сообщество.
Если у вас нет руководителя (так бывает только если вы ген. директор) или вы сам являетесь руководителем вам необходимо обратиться к вышестоящему руководителю с этими вопросами.
В самом первом моем сообщении у меня не было желания посмеяться над вами и уж тем более раздуть ЧСВ (перед кем его тут раздувать-то?), мне скорее показалась нелепой та ситуация, в которой вы оказались, и мой сарказм был направлен исключительно на нашу российскую действительность, которая допускает такие ситуации, а не на вас лично.