

import cv2
import numpy as np
from PIL import Image
img = cv2.imread('words.png', cv2.IMREAD_GRAYSCALE)
mask = img.min(axis=0) == 255.0
masked = np.ma.array(img[0, :], mask=mask)
slices = np.ma.notmasked_contiguous(masked)
pieces = [img[:, s] for s in slices]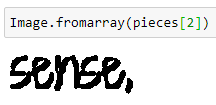
scaled = cv2.resize(img, None, fx=2.5, fy=2.5, interpolation=cv2.INTER_AREA) Простой
Простой
Простой
Средний
Простой
Простой
Простой
Средний