Здравствуйте!
Заранее извиняюсь за не совсем ясное, как по мне, объяснение своей проблемы.
В вузе работаю над проектом, суть которого заключается в парсинге данных из Excel с последующем сохранением в PostgreSQL.
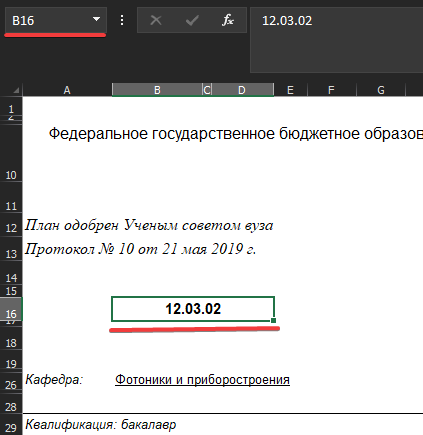
Мне дали таблицу, попросили написать для неё программу. Я написал, данные успешно парсились. Но затем мне скинули ещё с десяток таблиц, и вот тут начались проблемы. Таблицы несколько отличаются в том плане, что данные, которые в первой таблице находятся на n-ой строчке и j-ом столбце (1 скриншот), в других таблицах могут находиться в иных местах (2 скриншот).
И таких не совпадающих по координатам ячеек в таблицах достаточно много.
А я написал программу, которая начинает парсить данные с конкретного столбца и конкретной строчки конкретной таблицы, ибо предполагал, что таблицы по структуре будут одинаковы.
Вопрос: как
грамотно написать парсер таким образом, чтобы он не был привязан к определенным строчкам и столбцам при поиске конкретных данных и, соответственно, не ломался, если нужные данные в таблице находятся, условно говоря, в ячейке C16, а не B16, как предполагалось. Как можно учесть все эти несоответствия?
Спрашиваю не потому, что сам не хочу напрягаться, а потому, что меня самого интересует, как можно написать такую "адаптивную" программу без костылей с кучей if-else и циклов for, и возможно ли такое в принципе.
Не знаю, нужна эта информация или нет, но:
1) Использую язык Java и библиотеку apache.poi.
2)
Сам проект на GitHub