
href элементов a.Ссылка на страницу в репозитории на гите.(премодерация ругается, видимо из-за домена ресурса)
<selenium.webdriver.remote.webelement.WebElement (session="45a0063f8da9f78a78c38b201240c24a", element="6b43db73-2b1a-4886-9237-f493f7693539")>href из него получить не могу. Подскажите, в чем может быть ошибка? Возможно, есть какой-то другой способ получить ссылки из элементов?
Соответственно, href из него получить не могу
<div> с классом testCard. У div нет и никогда не было аттрибута href.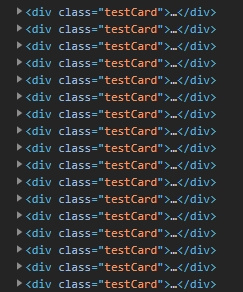
class.href с вложенного в div элемента а,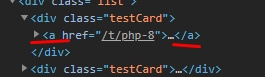
div найти элементы a, затем у них уже брать href.for el in slide_elems:
# Находим вложенный тег <a>
tag_a = el.find_element_by_tag_name('a')
print(tag_a.get_attribute('href'))

//*[@class='testCard']/adef parse(self):
self.go_to_questsions_page()
slide_elems = self.driver.find_elements_by_class_name("testCard")
f = open("text.txt", "w")
f.write(str(slide_elems))
for el in slide_elems:
print(el.get_attribute('href'))