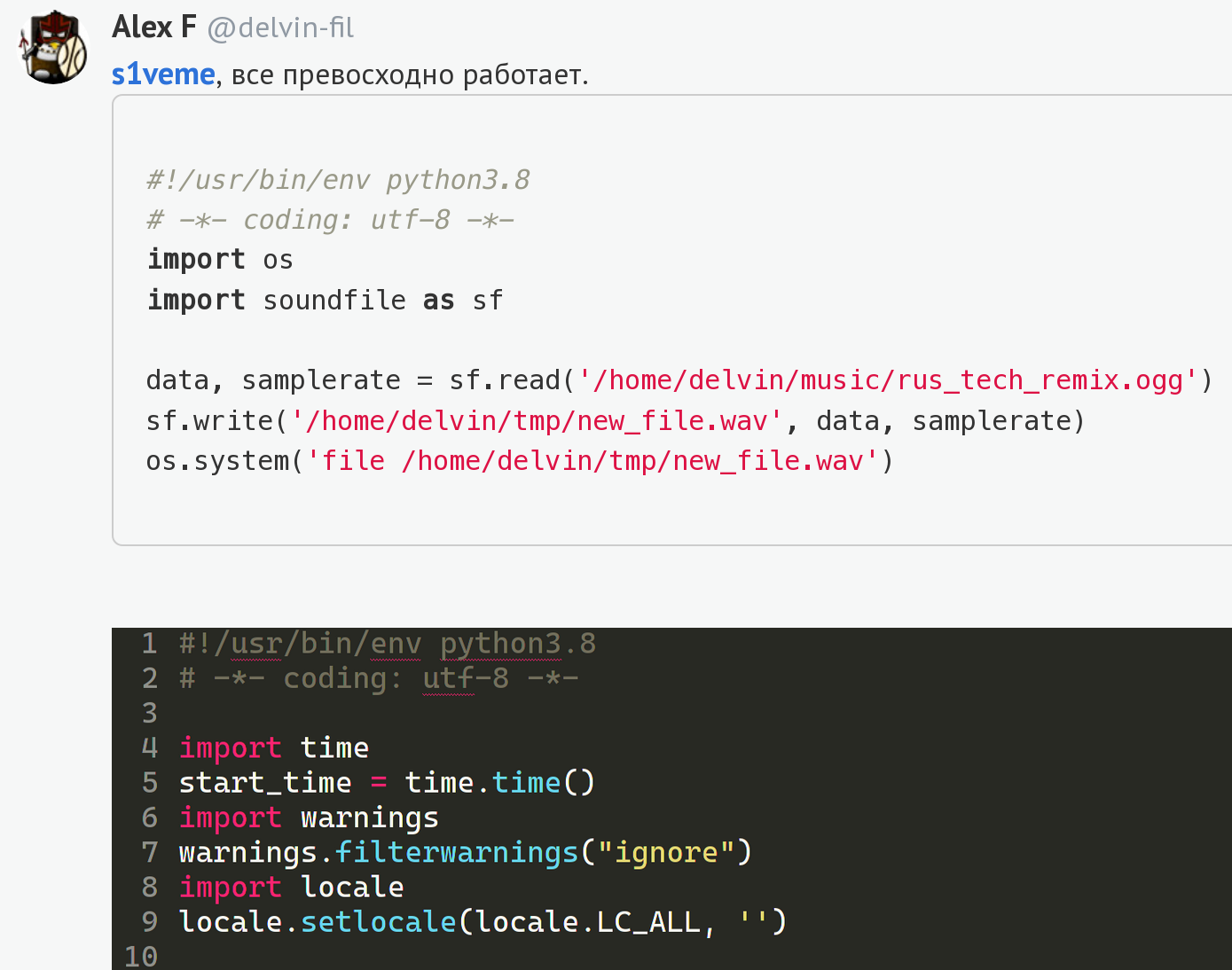
import soundfile as sf # pip install pysoundfile
data, samplerate = sf.read('existing_file.ogg')
sf.write('new_file.wav', data, samplerate)
import speech_recognition as sr
sinput = '/tmp/test.wav'
r = sr.Recognizer()
harvard = sr.AudioFile(sinput)
with harvard as source:
audio = r.record(source)
out = r.recognize_google(audio)
print (out)
 Простой
Простой
Простой
Средний
Простой
Простой
Простой
Средний