Вас интересует Feature Selection. en.wikipedia.org/wiki/Feature_selection . Куда дальше копать, сейчас подсказать не могу. Если интересует просто уменьшение размерности, а не какая фича важнее, то можно использовать PCA. Самые популярные алгоритмы реализованы в библиотеках Machinle learning типа WEKA.
Для правильного вопроса надо знать половину ответа
По известному набору точек можно лишь предположить вид функции, например набор (-1, 0), (0, 0), (1, 0) может принадлежать как прямой y=0, так и синусоиде y=sin(πx) или полиному y=x3-x. Обычно вид функции выбирается из физической модели процесса, для которого получены данные.
На самом деле, в наборах {a1, a2 ... an} не 3, а где-то 50 значений, т.е F - функция от кучи переменных. Наборы (a1, a2 .. an, Rn) можно вычислить сколь угодно раз (вычисляет программа по неизвестной мне формуле).
На самом деле задача скорее в следующем. При изменении некоторых переменных, значение F изменяется слабо или не изменяется вообще (таких переменных много). Нужно найти переменные не влияющие/сильно влияющие на значение F. Т.е есть 2 массива:
{a1, a2 .. an, F()=R1}, {b1, b2 .. bn, F()=R2}
и нужо найти корреляцию между ними.
Может быть, просто посчитать частную производную F по каждой из переменных (как (F(a1+da,a2,..,an)-F(a1,a2,...,an))/da) в нескольких точках, и выбрать переменную, для которой среднее квадратическое будет минимальным?
Для правильного вопроса надо знать половину ответа
Если заранее неизвестен хотя бы общий вид функции, то, по моему, проще дизассемблировать программу и разобраться в вычислениях, чем пытаться определить взаимозависимости между 50 параметрами. Например, для такой функции двух переменных
зависимость от y сильно проявляется только в малой области значений x в районе x=b. А ведь функция может быть и кусочно-непрерывной, например
Про Feature Selection есть какая нибудь литература на русском?
В конце en.wikipedia.org/wiki/Feature_selection есть список с софтом. Может кто знает примеры/мануалы (желательно также на русском) практического применения?


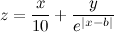
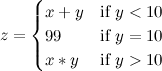
 Простой
Простой
 Простой
Простой

