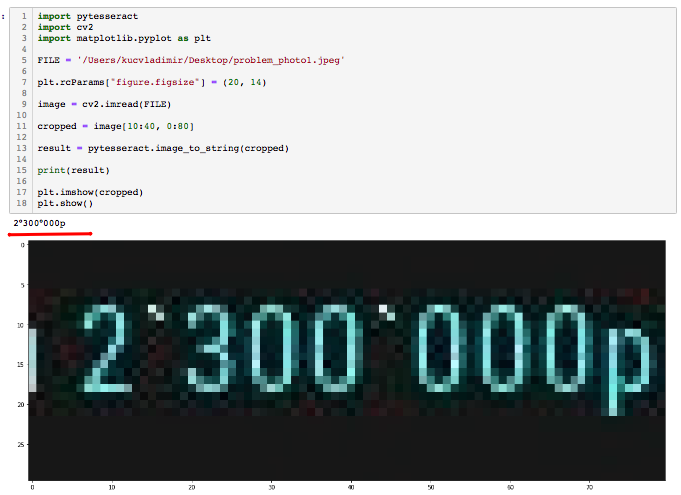
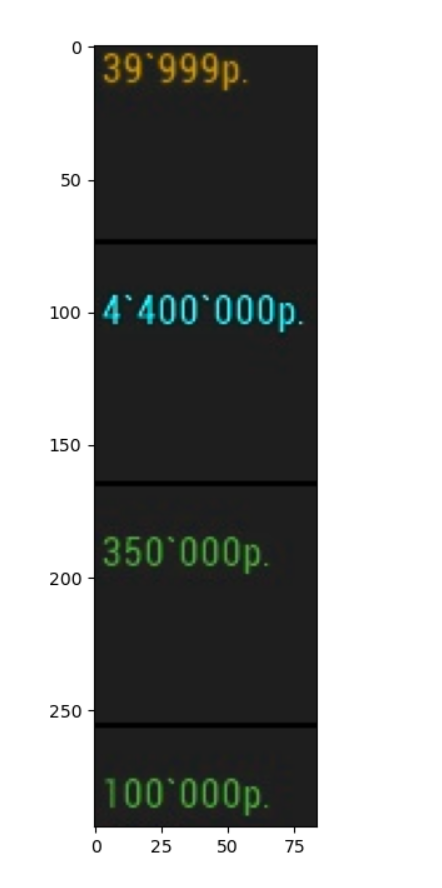
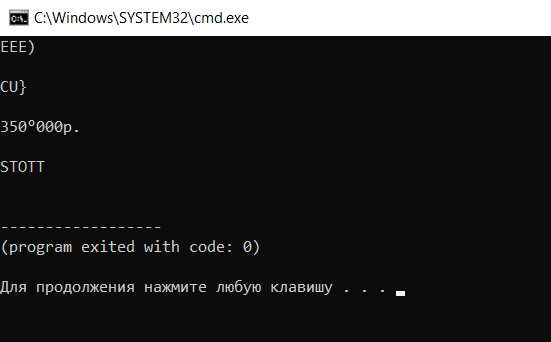
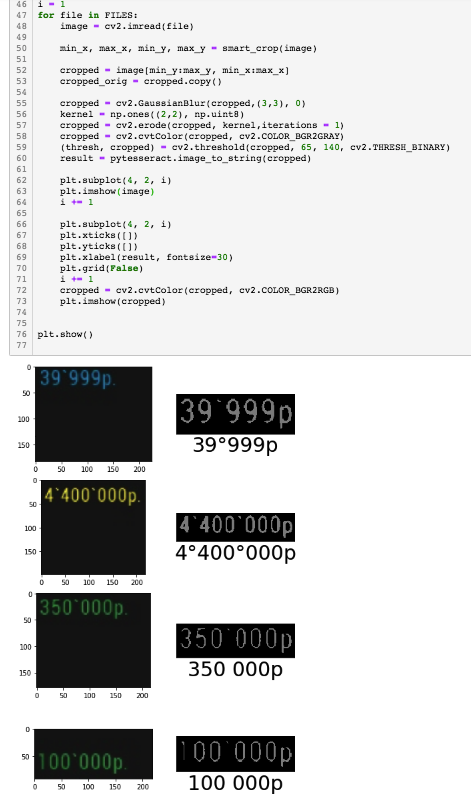
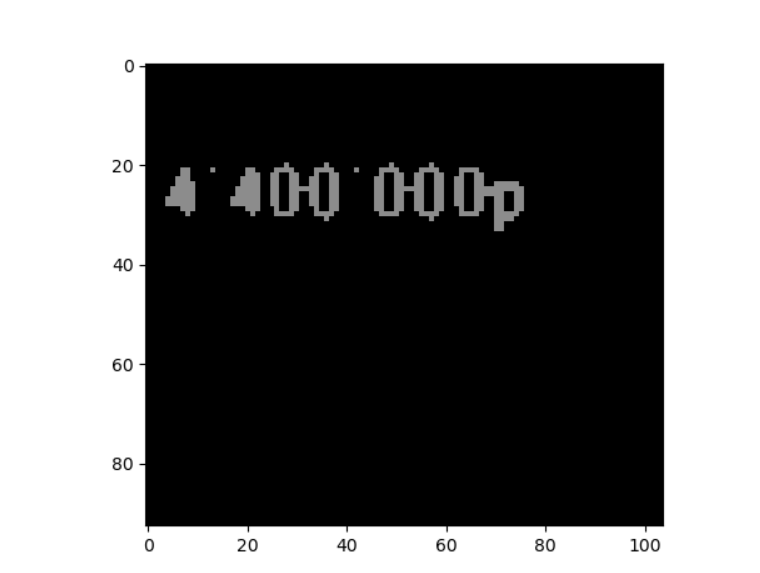
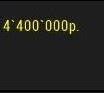
Мне нужно распознавать цифры и буквы на картинках. Я решил использовать tesseract. Но из-за некоторых трудностей с распознаванием, мной было принято решение обрезать фото, и распознавать только нужные мне области.Был написан код которые это делал с помощью Pillow.Но тут началось что-то странное. При обрезании фото 'руками' с помощью сил винды, все супер распознает. Но при распознавании изображения обрезанного кодом, tesseract из 10 распознаваний ни разу не смог даже близко приблизится к предыдущему результату. Может быть кто-то сталкивался с такой проблемой? Или же может знает кто как можно обрезать фото без Pillow? Так как туториалы нашел только по данной библиотеки. Дальше идет код который обрезает фото.
import re
from PIL import Image
def crop(image_path, coords, saved_location):
image_obj = Image.open(image_path)
cropped_image = image_obj.crop(coords)
cropped_image.save(saved_location)
cropped_image.show()
addres = (627, 541, 906, 631)
if __name__ == '__main__':
image = 'image/shot_003 (2).jpg'
crop(image, addres, 'image/shot_001.jpg')
Спасибо!