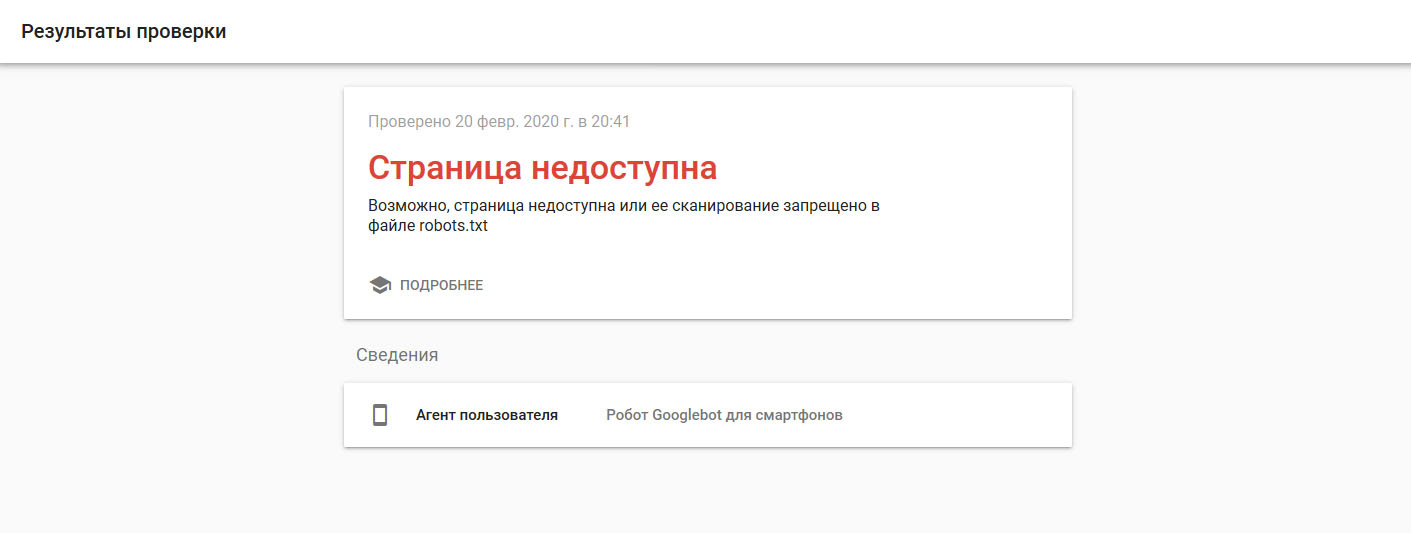
Две недели назад добавил сайт в гугл, полазив по поиску наткнулся на статейку где описывается что где нужно проверять, вот к примеру "проверка оптимизации для мобильных устройств", проверил и мне дало такой вот результат
сам robots.txt выглядит так
User-agent: *
Disallow:
Host: https://.............
Sitemap: https://............./sitemap.xml
проблема в нем или просто еще поисковик не "разогнался"?
вроде как для всех ботов разрешено, запрещения никакого нет...
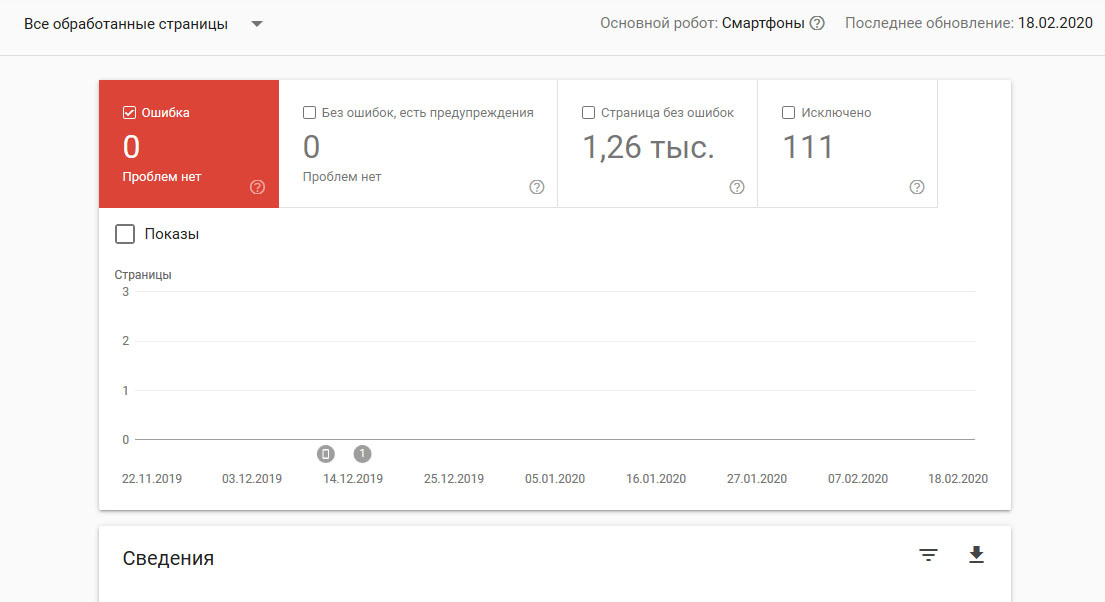
покрытие выглядит так
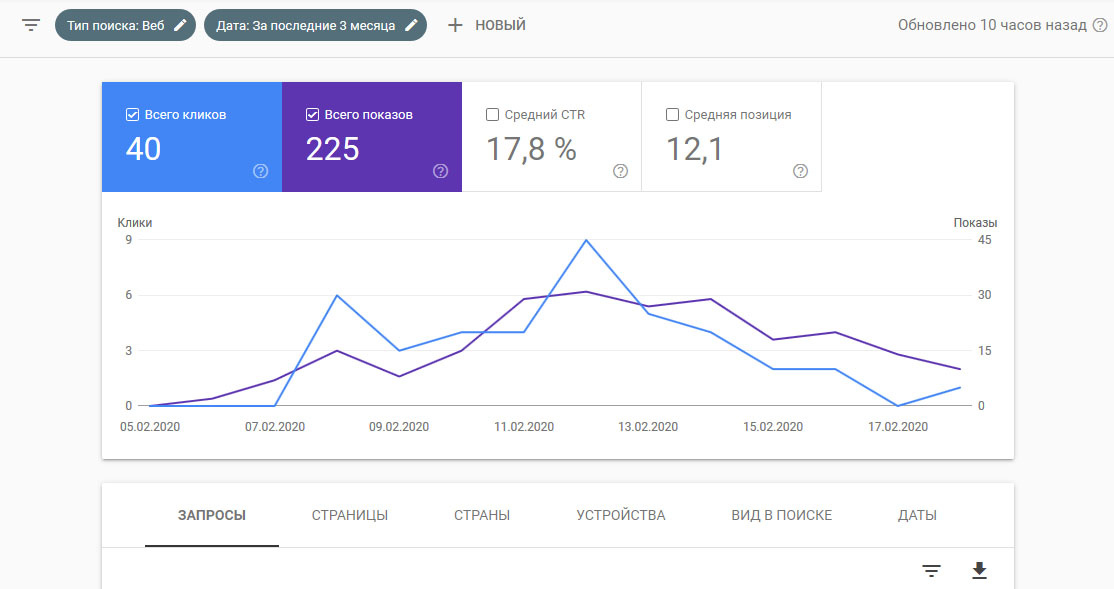
эффективность так
подскажите, я что-то не так делаю, в чём то могут быть проблемы или все нормально и нужно просто ждать?


 Простой
Простой
