Не так давно завершилась квалификация Яндекс.Алгоритм.2015. Формат раунда такой, что дается 100 минут и 7 задач, которые необходимо решить. Задачи не очень сложные, но тем не менее, возникали определенные трудности в решение некоторых из них. В основном это лимиты времени выполнения (TL). В общем, хотелось бы, чтобы к этой теме присоединились участники соревнования; хотелось бы устроить что-то типа обсуждения способов решения данной задачи, мне кажется, это будет очень полезно для каждого участника, в преддверии основной части соревнования, впрочем, любой желающий, может поучаствовать в решение данной задачи.
Условие:
Иван — обычный пользователь интернета. Одна из любимых игр Ивана — «Шляпа», в которой нужно быстро объяснять загаданное слово. Для того, чтобы играть было интересно, он ищет необычные слова в интернете, задавая различные поисковые запросы. Ивана всегда интересовало, почему один документ оказывается выше другого в поисковой выдаче. Задав запрос об этом в поиске Яндекса, Иван выяснил, что документы упорядочиваются автоматически по убыванию релевантности документов. А релевантность, в свою очередь, вычисляется по формуле, подобранной специальным алгоритмом. В этой задаче мы будем использовать упрощенную версию формулы релевантности — линейную комбинацию параметров документа. Формула ранжирования задаётся N параметрами (a1, a2, …, aN), а каждый документ описывается N числовыми параметрами (f1, f2, …, fN). Релевантность же определяется по формуле:
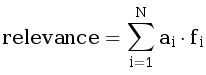
Интернет очень быстро изменяется, и некоторые документы могут меняться несколько раз в минуту. Конечно, после этого необходимо изменить и некоторые параметры этого документа. Можете ли вы в условиях изменяющихся параметров документов находить самые релевантные?
Формат ввода:
В первой строке входных данных записано одно целое число N (1 ≤ N ≤ 100) — количество параметров в формуле ранжирования. Вторая строка содержит N целых чисел ai (0 ≤ ai ≤ 10^8). В третьей строке входных данных записано одно целое числа D (10 ≤ D ≤ 100 000, N * D ≤ 100 000) — количество документов для ранжирования. Далее в D строках записано по N целых чисел fi,j (0 ≤ fi,j ≤ 10^8) — числовые параметры i-го документа. Следующая строка содержит одно целое число Q (1 ≤ Q ≤ 100 000) — количество запросов к системе ранжирования. Следующие Q строк описывают запросы. Запрос на выдачу самых релевантных документов задаётся парой 1 K (1 ≤ K ≤ 10). Запрос на изменение параметра документа задается четвёркой 2 d j v (1 ≤ d ≤ D, 1 ≤ j ≤ N, 0 ≤ v ≤ 10^8) и означает, что j-й параметр у d-го документа становится равным v.
Формат вывода:
После каждого запроса первого типа выведите в одну строку порядковые номера K самых релевантных документов в порядке убывания релевантности (числа следует разделять одиночными пробелами). Гарантируется, что все документы в любой момент времени имеют различные значения релевантности.
Ограничения:
Ограничение времени: 2.5 секунд
Ограничение памяти: 64Mb
Ввод: стандартный ввод или input.txt
Вывод: стандартный вывод или output.txt
Пример:Ввод:
2
1 100
10
1 2
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 1
4
1 2
1 10
2 4 1 1000
1 10
Вывод:
1 10
1 10 9 8 7 6 5 4 3 2
4 1 10 9 8 7 6 5 3 2
Ниже мой вариант решения на java:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class Task3_2
{
static class CPair
{
public int rel;
public int num;
public CPair(int r, int n)
{
rel = r;
num = n;
}
}
static class CRelComp implements Comparator<CPair>
{
public int compare(CPair p1, CPair p2)
{
return p2.rel - p1.rel;
}
}
static int m_N;
static int m_D;
static int m_Q;
static int[] m_listA;
static int[][] m_listD;
static int[][] m_listQ;
static int[] m_listR;
public static void main(String[] args) throws IOException
{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
m_N = Integer.valueOf(br.readLine()); //количество параметров - N.
String[] line = br.readLine().split(" "); //набор параметров - Ai.
m_listA = new int[m_N];
for (int n = 0; n < m_N; n++)
m_listA[n] = Integer.parseInt(line[n]);
m_D = Integer.valueOf(br.readLine()); //количство документов - D.
m_listD = new int[m_D][m_N];
for (int d = 0; d < m_D; d++)
{
line = br.readLine().split(" "); //набор параметров Di-го документа - F.
for (int n = 0; n < m_N; n++)
m_listD[d][n] = Integer.parseInt(line[n]);
}
m_Q = Integer.valueOf(br.readLine()); //количество запросов к системе - Q.
m_listQ = new int[m_Q][4];
for (int q = 0; q < m_Q; q++)
{
line = br.readLine().split(" "); //набор параметров Qi-го запроса.
for (int i = 0; i < line.length; i++)
m_listQ[q][i] = Integer.parseInt(line[i]);
}
m_listR = new int[m_D];
for (int d = 0; d < m_D; d++) //расчет релевантностей.
for (int n = 0; n < m_N; n++)
m_listR[d] += m_listA[n] * m_listD[d][n];
//выполнение запросов.
for (int q = 0; q < m_Q; q++)
{
if (m_listQ[q][0] == 1)
{
ArrayList<CPair> pairs = new ArrayList<CPair>();
for(int r = 0; r < m_D; r++)
pairs.add(new CPair(m_listR[r], r + 1));
Collections.sort(pairs, new CRelComp());
for (int i = 0; i < m_listQ[q][1]; i++)
System.out.print(pairs.get(i).num + " ");
System.out.println();
}
else
{
int d = m_listQ[q][1] - 1;
int j = m_listQ[q][2] - 1;
int v = m_listQ[q][3];
int oldPart = m_listD[d][j] * m_listA[j];
int newPart = v * m_listA[j];
int div = oldPart - newPart;
m_listR[d] -= div;
m_listD[d][j] = v;
}
}
}
}
Программа заваливается на 22 тесте с лимитом времени TL.









