Доброго времени суток!
Стоит такая задача: посчитать для каждого символа количество его вхождений в файле. Для этого я использую wifstream, дабы получить сам символ, а потом добавляю его в unordered_map, если такого ещё не было. Ну либо инкрементирую количество на единицу.
С английским текстом всё работает отлично, но только не с другими (например, русским и монгольским).
Сам код:
#include <iostream>
#include <fstream>
#include <unordered_map>
#include <Windows.h>
int main(int argc, char* argv[])
{
SetConsoleOutputCP(65001);
if (argc == 1) {
std::cerr << "Error: Alphabet file not specified\n";
return 1;
}
std::unordered_map <wchar_t, int> alphabet;
std::wifstream alphabet_file(argv[1]);
if (!alphabet_file) {
std::cerr << "Error: Alphabet file not found\n";
return 1;
}
if (alphabet_file.is_open()) {
wchar_t ch;
while (alphabet_file.get(ch)) {
if (alphabet.find(ch) != alphabet.end())
alphabet[ch] = alphabet[ch] + 1;
else
alphabet.insert(std::make_pair(ch, 1));
}
}
for (auto i = alphabet.begin(); i != alphabet.end(); i++) {
if (i->first == '\n')
std::wcout << "\\n" << ": " << i->second << std::endl;
else
std::wcout << i->first << ": " << i->second << std::endl;
}
alphabet_file.close();
return 0;
}
Вот как программа читает английский файл:
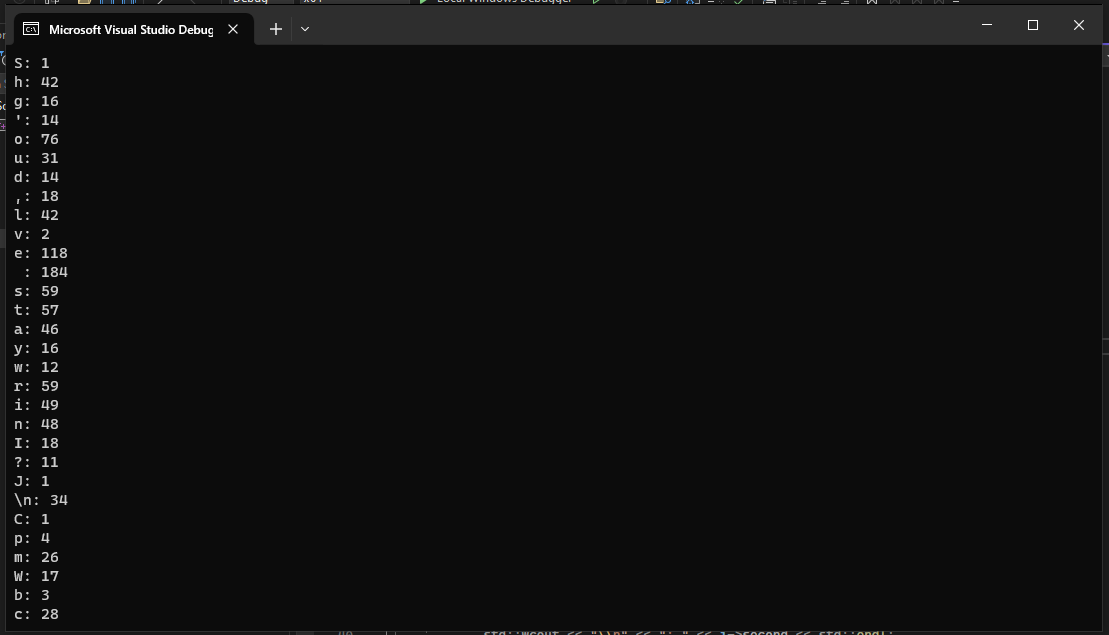
А вот как русский файл:
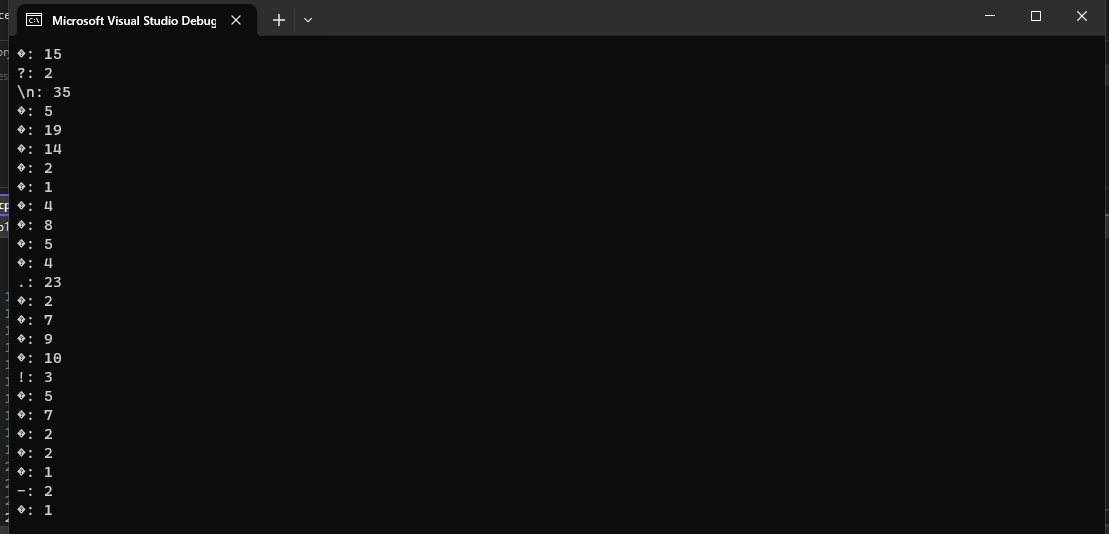
Вот какой первый символ хранит в себе unordered_map, хотя должен был хранить символ русской буквы "З".
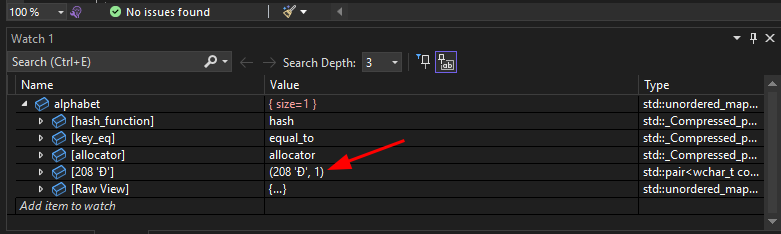
Все текста сохранены в обчном файле с форматом .txt в UTF-8. Пробовал менять на UTF-16, но и это не помогло. Вообще нет представления о том, как это починить :(




 Простой
Простой


