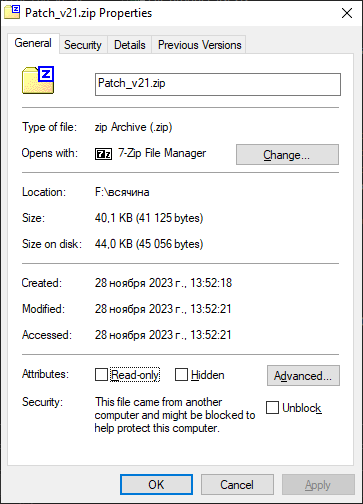
При скачивании файлов на Windows свойство "Дата создания" у файла не та, которая является моментом начала скачивания файла, а непосредственно дата создания файла.
Например при скачивании этого файла в Проводнике в Windows 10 дата создания указана 21.11.2023 22:45
https://www.upload.ee/files/15992284/Patch_v21.zip.html
Хотя сейчас 28.11.2023 (текущая дата когда я его скачиваю).
Насколько мне известно свойства файла, такие как дата создания и дата изменения, которые отображаются в Проводнике - не хранятся в теле самого файла. Их хранит файловая система где-то в своей "базе данных".
Получается когда я загружаю файл через браузер на сервер - помимо самого файла (то есть байт которыми является этот файл) браузер у файловой системы запрашивает все свойства файла и тоже отправляет их на сервер? И потом при скачивании файла, сервер также отдает все свойства файла?
- Если да, то как это происходит? (свойства файла передаются в общей массе байт при загрузке скачивании/файла или в http заголовках или как?)
- На сервере свойства файла тоже хранятся в файловой системе или в БД или по разному в зависимости от того как настроен сервер?
- Браузер загружает вообще все свойства файла которые у него есть в файловой системе? (наверняка же есть как-бы кастомные свойства, которые можно заполнить разными данным по несколько килобайт - такие свойства тоже будут загружаться и скачиваться?)
- Расширенные аттрибуты файлов в данном контексте (например те, которые в macOS можно посмотреть через xattr) это тоже самое что и свойства файла и они также будут загружаться и скачиваться или они не относятся к свойствам файла?



 Средний
Средний