Имею следующий код:
import cv2
from PIL import Image, ImageEnhance, ImageFilter
import pytesseract
# Открываем файл
img = Image.open('C:\Screenshots\screenshot1.png')
# Увеличиваем контрастность:
enhancer = ImageEnhance.Contrast(img)
img = enhancer.enhance(2)
# Изменяем размер
img = img.resize((1200, 600))
# Обрезаем лишнее
img = img.crop((200,140,1140,435))
# Преобразуем в черно-белый рисунок
thresh = 200
fn = lambda x: 255 if x > thresh else 0
reconv = img.convert('L').point(fn, mode='1')
reconv.save("c:\\Screenshots\pescreen1.png")
# Пытаемся считать цифры
image1 = cv2.imread("C:\Screenshots\pescreen1.png")
string1 = pytesseract.image_to_string(image1)
print(string1)
Исходное изображение

Редактированное изображение
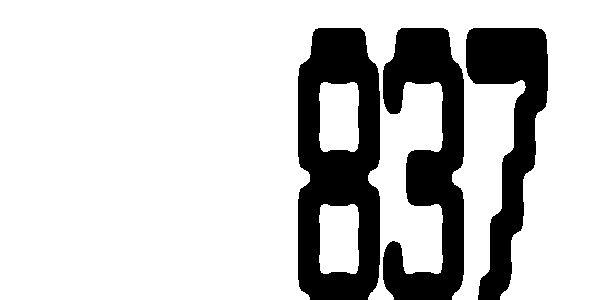
Ответ выдаёт: Hai
Если в коде изменить размер
# изменяем размер
img = img.resize((300, 150))
# Обрезаем лишнее
img = img.crop((0,0,280,110))

Выдаёт : 027
Но такой точности не достаточно. Потому что в дальнейшем буду работать с большим количеством цифр.

