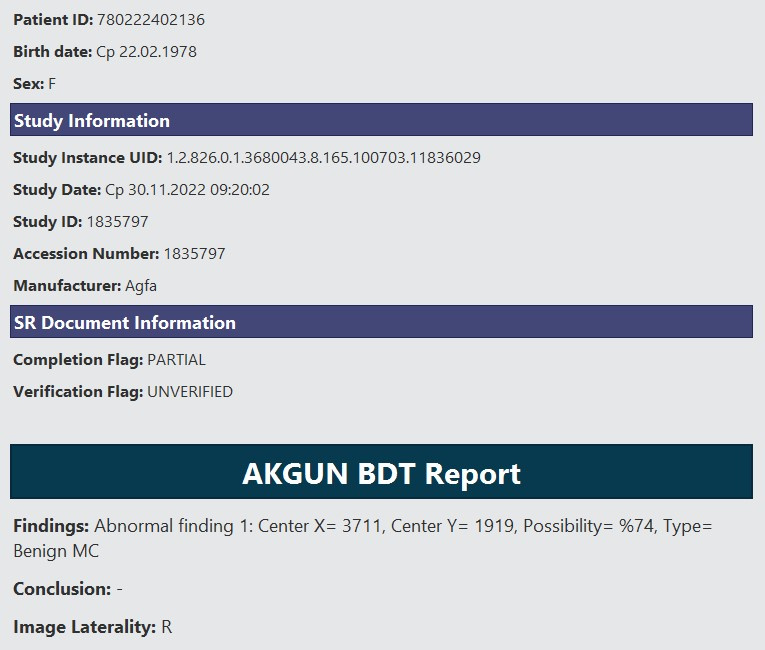
В системе Linux есть миллионы файлов со следующим содержимым:
id: 123456789012 #числа в каждом файле разные но всегда состоят из 12 цифр
x=123 y=1234 #здесь тоже числа разные, могут состоять максимум из 4 цифр
Laterality=R #здесь во всех файлах значение либо R либо L
нужно вывести только значения и записать построчно, как на примере:
123456789012 123 1234 R
234567890123 2345 234 L
и т.д.
с помощью этой команды я смог вывести и записать построчно только значения id в txt-файл со всех файлов в каталоге и в подкаталогах:

получилось так:
123456789012
234567890123
и т.д.
у меня не получается придумать команду с условием, что если в файле нет строк с "x=" либо "y=" либо "Laterality", то ничего с этого файла записывать не нужно, а если в файле все строки имеются то записать их значения (значения из одного файла в одну строку, разделив пробелом как указал на примере "123456789012 123 1234 R")