
<h1>test world of world</h1>
<div>testworld of world</div>
<h1> test world of world</h1>(?<=<h1>).*(world).*(?<=<\/h1>), но находит только первое слово.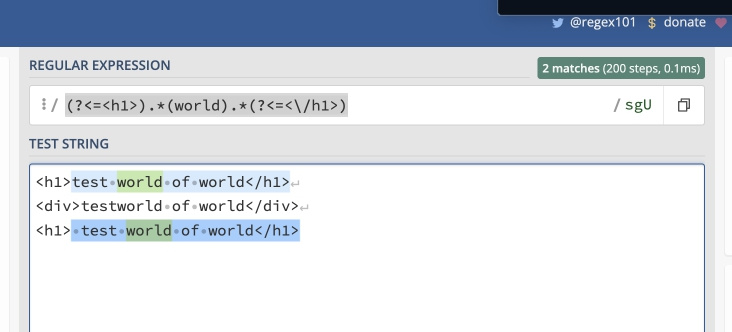


Или может такую задачу нельзя решить регуляркой, и нужно разбивать на две регулярки?
Простой
 Простой
Простой

