Пишется домашний проект, в котором есть веб-редактор текста (plaintext) с желаемой возможностью прикреплять по id-ссылке ресурсы (картинки, документы и тому подобное). Выход проекта, во избежание зоопарка - единый бинарник (rust, его стэком и ограничен).
Не выходит нагуглить алгоритм согласованного сохранения текста и ресурсов, чтобы by-design было, по приоритетам, следующее:
1. никаких битых ссылок на ресурс
2. диск не засоряется при удалении ссылки на ресурс или прерывании процесса обновления текста, содержащего ссылку
3. минимальное число записей, а лучше и чтений диска
4. текстов и ресурсов может быть много
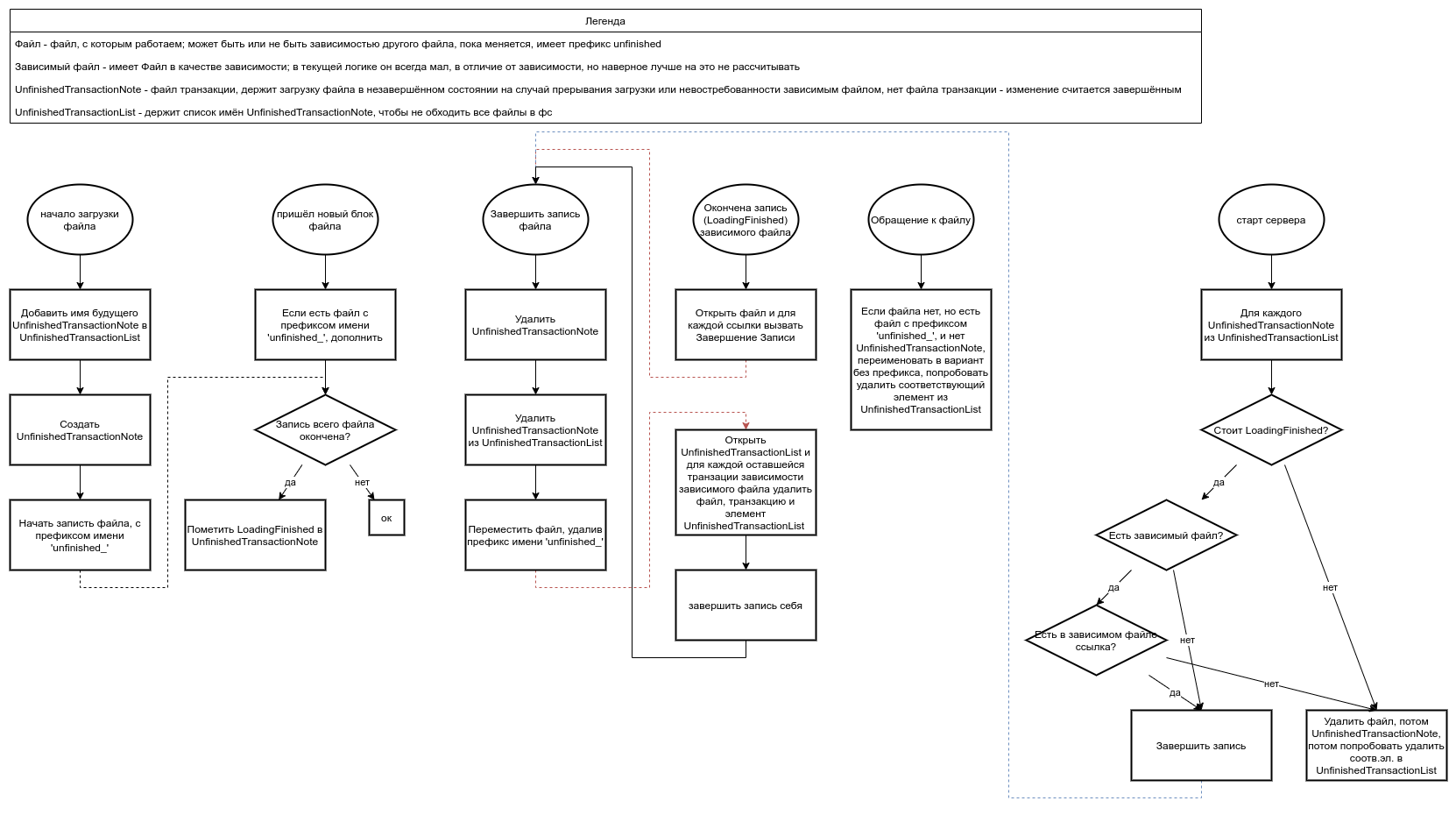
По второму полагаю нужна 'чистка' как часть инициализации сервера, по третьему может как дополнительный хак - удалять небольшие ресурсы не сразу, а по таймеру на случай, если пользователь передумал удалять. А накидал алгоритм пока такой:
Выглядит нагружено, много обращений к диску, наверняка какие-то шаги имеют подводные камни, да и подход в алгоритме может быть просто неверен
Так что нужна помощь
Спасибо