Имеется датасет из 2 колонок в каждом по 4000 наблюдений. При тестовой валидации где окно состоит из 100 значений и предсказание на 1 шаг все работает отлично, но как предсказать на N шагов за пределы датасета?
Обучающая выборка 3500, Тестовая 500, окно включает 100 наблюдений
X_train.shape(3400, 100, 2) y_train.shape(3400,)
X_test.shape(400, 100, 2) y_test.shape(400,)
делил по стандартной схеме:
X = []
y = []
for i in range(self.__seq_length, train.shape[0]):
X.append(train[i-self.__seq_length: i])
y.append(train[i, 0])
return np.array(X), np.array(y)
Предик по первой колонке одно значение.
Как предсказать за пределы датасета?
Ничего не придумал как двигать окна запустив цикл на 100 итераций, окно для второй колонки двигать влево, а окно для первой колонки вправо каждый раз дополняя новыми предиктами в итоге формировался нужный массив (1, 100, 2)
predicted = []
for i in range(self.__seq_length + 1):
p = None
y = []
if i == 0:
window = self.__dataset[-(self.__seq_length + i):, 1]
y = self.__dataset[-(self.__seq_length + i):, 0]
else:
window = self.__dataset[-(self.__seq_length + i):-i, 1]
ls = -(self.__seq_length - i)
y = []
if ls < 0:
pred_next_window = self.__dataset[ls:, 0]
for j in range(pred_next_window.shape[0]):
val = pred_next_window[j]
y.append(val)
for j in range(len(predicted)):
val = predicted[j]
y.append(val)
y = np.array(y)
else:
for j in range(len(predicted)):
val = predicted[j]
y.append(val)
y = np.array(y)
new_seq = np.transpose(np.array((y, window)))
print(str.format('iteration: {0}\n{1}', i + 1, new_seq))
scale = MinMaxScaler()
new_seq = scale.fit_transform(new_seq)
new_seq = np.reshape(new_seq, (1, new_seq.shape[0], new_seq.shape[1]))
output = self.__model.predict(new_seq)
scale_ = self.__val_scale/scale.scale_[0]
predict = output*scale_
print(str.format('Next Value: {0}', predict))
predicted.append(predict[0, 0])
return np.array(predicted)
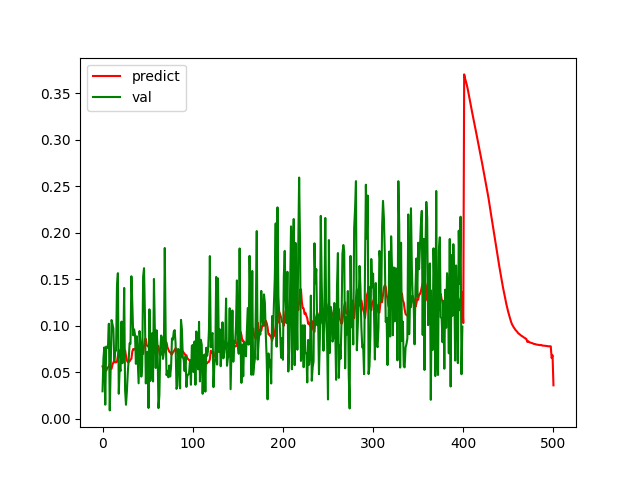
По итогу :
Пока предик тестовый красный график идет вместе с зеленым то что за зеленым графиком это уже манипуляции с перемещением окон, по итогу дичь как быть если я еще завишу от 2 колонки?

 Простой
Простой