

import requests
from bs4 import BeautifulSoup
url = 'https://blast.hk/members/181760/'
responce = requests.get(url)
soup = BeautifulSoup(responce.text,"lxml")
nick = soup.find('span',class_='username').text
print(nick)
# A-Waiterfrom urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html, "html.parser")
sibling = bsObj.find("table").find_previous_sibling
print(sibling())strikes = soup.find_all('strike') # Ищем все теги strike
for strike in strikes:
strike.decompose() # Удаляем все теги strike из дерева
soup2 = soup.find_all('a') # Теперь в обьекте soup DOM дерево без тегов strike
for x in soup2:
print(x.get('href')) # Ищем все ссылки/services/service1/
/services/service3/Вопрос: какова вероятность, что manjaro виноват, поставлю Винду и будет нормально?
Меня больше смущает, что после небольшой трясучки ноута работает.
HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Internet Explorer\Main\FeatureControl\FEATURE_BFCACHEпараметр iexplore.exe(DWORD) со значением 0. Если нет, тогда создайте
Селениум не предлагать, т.к нужно написать бота без демонстрации и с быстрой скоростью- если будете ставить лайки по 10 тыс. в секунду, то вам и ассемблер не поможет, вас забанят за накрутку (неуверен, но так думаю).
import requests
from bs4 import BeautifulSoup
def trade_spiders (page):
url = 'https://1xbe#/live/'# + str(page)
source_code = requests.get(url)
soup = BeautifulSoup(source_code.text, 'html.parser')
main_title = soup.find_all('div', class_="c-events__name")
for title in main_title:
print(title.find('span',class_='c-events__liga').text.strip())
trade_spiders(1)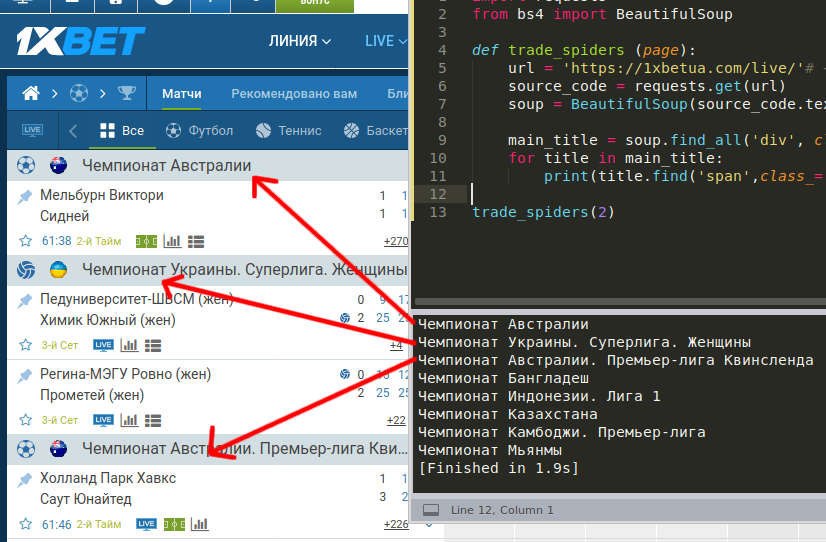
curl https://bootstrap.pypa.io/get-pip.py | pythonpip install --upgrade setuptools
Межпроцессное взаимодействие