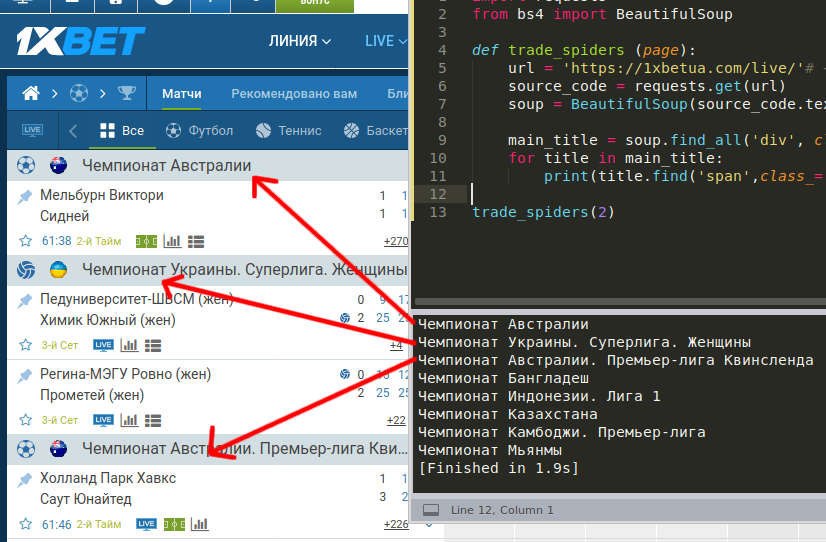
1) Как сказал уже
Dr. Bacon , нужно использовать отладчик. Ну конкретно в данном примере можно обойтись и print.
2) Также у меня по адресу "
https://1xbet#/live/1"(пробовал и другие сайты, в том числе и белорусский) возвращает 404.
3) Там нет тега 'a' с классом 'c-events__name', но есть тег 'div'
4) Как мне кажется, лучше использовать функцию 'trade_spiders' в цикле, чем цикл внутри функции(это касается только данного примера!)
import requests
from bs4 import BeautifulSoup
def trade_spiders (page):
url = 'https://1xbe#/live/'# + str(page)
source_code = requests.get(url)
soup = BeautifulSoup(source_code.text, 'html.parser')
main_title = soup.find_all('div', class_="c-events__name")
for title in main_title:
print(title.find('span',class_='c-events__liga').text.strip())
trade_spiders(1)