Error: Failed to load module @rollup/rollup-win32-x64-msvc. Required DLL was not found. This error usually happens when Microsoft Visual C++ Redistributable is not installed. You can download it from https://aka.ms/vs/17/release/vc_redist.x64.exe
import requests
base_url = "https://www.ursus.ru/catalogue/zashchita_ot_padeniy_s_vysoty/page-"
pages = 8
for i in range(1, pages + 1):
print(f"Page: {i}")
print(f"{base_url}{i}/")
requests.get(f"{base_url}{i}.")headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Mobile Safari/537.36"
}data = requests.get(url, headers=headers)import requests
from bs4 import BeautifulSoup
url = "https://realt.by/sale-flats/object/2562548/"
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Mobile Safari/537.36"
}
data = requests.get(url, headers=headers)
soup = BeautifulSoup(data.text, features="html.parser")
img = (
soup.find("div", attrs={"class": "swiper-wrapper"})
.findAll("img", class_="blur-sm scale-105")[1]
.get("src")
)
print(img)https://static.realt.by/thumb/c/600x400/6f57b1d409f96f2b1ede7f082f120b50/ja/e/site15nf8eja/7c30f38145.jpg
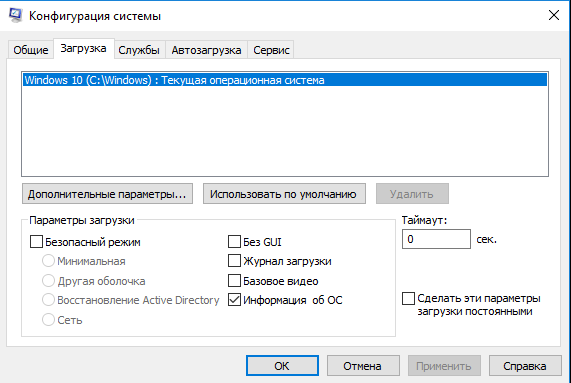
Open a new command prompt as administrator.
Type the following command:net stop dps. Hit the Enter key.
Now, execute the following command:del /F /S /Q /A "%windir%\System32\sru\*".
Finally, execute the commandnet start dps
Sub ExtractURL()
Dim rng As Range
For Each rng In Selection
rng.Offset(0, 1).Value = rng.Hyperlinks(1).Address
Next rng
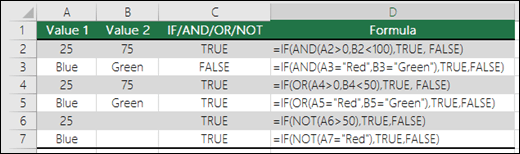
End SubAND – =IF(AND(Something is True, Something else is True), Value if True, Value if False)
OR – =IF(OR(Something is True, Something else is True), Value if True, Value if False)
NOT – =IF(NOT(Something is True), Value if True, Value if False)