pip install bs4 . а также requests pip install requests, через Win+R или cmdpip install bs4 . а также requests pip install requests, через Win+R или cmditem = soup.find('a', class_="sih-inspect-magnifier")
print(item[href])

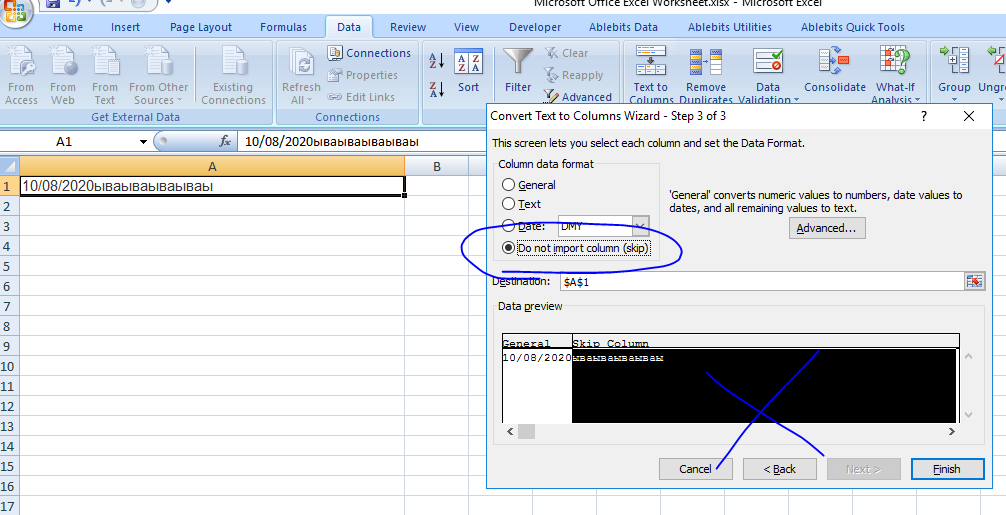
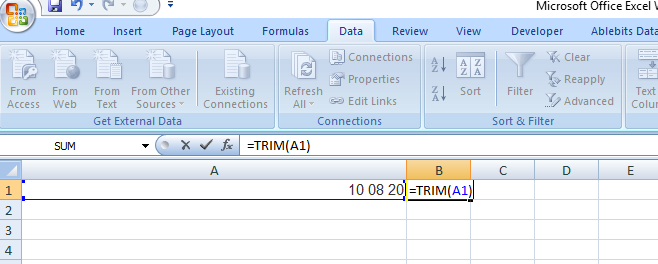
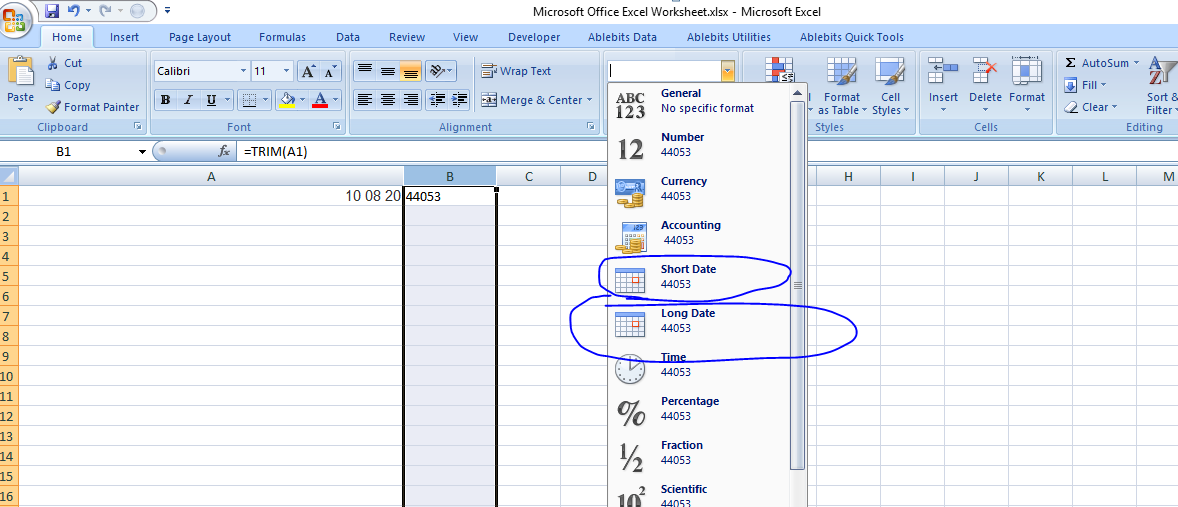
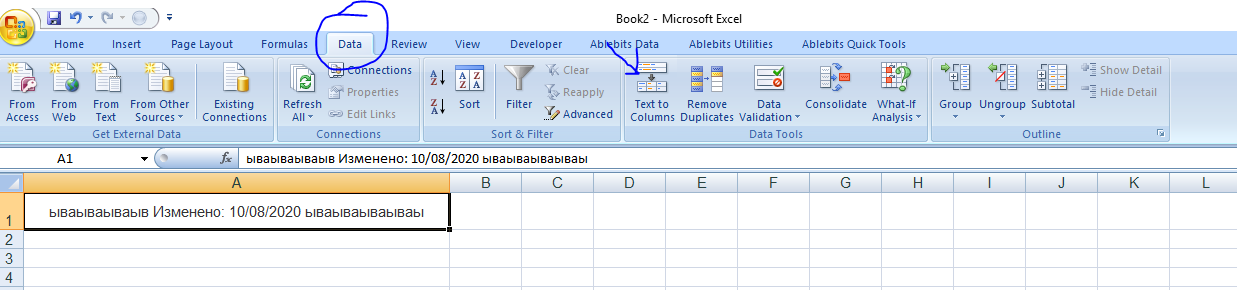


If you look at the source code for the page, you'll see that some javascript generates the webpage. What you see in the element browser is the webpage after the script has been run, and beautifulsoup just gets the html file. In order to parse the rendered webpage you'll need to use something like Selenium to render the webpage for you.
So, for example, this is how it would look with Selenium:
from bs4 import BeautifulSoup import selenium.webdriver as webdriver url = 'http://instagram.com/umnpics/' driver = webdriver.Firefox() driver.get(url) soup = BeautifulSoup(driver.page_source) for x in soup.findAll('li', {'class':'photo'}): print x
soup.findAll('li', {'class':'photo'}) меняете на ваши нужды