from itertools import groupby
from operator import itemgetter
data = [
{'group': 'style', 'name': 'Классика'},
{'group': 'style', 'name': 'Модерн'},
{'group': 'type', 'name': '2-х комнатная квартира'}
]
ig = itemgetter('group')
result = [list(group) for key, group in groupby(sorted(data, key=ig), ig)]from collections import defaultdict
data = [
{'group': 'style', 'name': 'Классика'},
{'group': 'style', 'name': 'Модерн'},
{'group': 'type', 'name': '2-х комнатная квартира'}
]
result = defaultdict(list)
for item in data:
result[item['group']].append(item)
result = list(result.values())search_result = comp.find(...)
if search_result is not None:
comp_list.append({'title': search_result.get_text(strip=True)})from itertools import dropwhile
key = '5'
state = {1: 'a', 'abc': 'b', 3.14:'c', None: 'v', '5': 'b', '6': 'n', '7': 'm'}
new_state = dict(dropwhile(lambda item: item[0] != key, state.items()))for k in state.copy():
if k != key:
del state[k]
else:
breakimport cv2
import numpy as np
from PIL import Image
img = cv2.imread('words.png', cv2.IMREAD_GRAYSCALE)
mask = img.min(axis=0) == 255.0
masked = np.ma.array(img[0, :], mask=mask)
slices = np.ma.notmasked_contiguous(masked)
pieces = [img[:, s] for s in slices]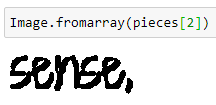
scaled = cv2.resize(img, None, fx=2.5, fy=2.5, interpolation=cv2.INTER_AREA)import cv2
import numpy as np
from PIL import Image
from itertools import product
N = 42
W = 200
H = 200
def distance(p1, p2):
y1, x1 = p1
y2, x2 = p2
return ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
canvas = np.zeros((H, W, 3), dtype=np.uint8)
centers = np.unravel_index(np.random.randint(0, W * H, N), canvas.shape[:2])
canvas[centers] = np.random.randint(0, 256, (N, 3))
centers = list(zip(*centers))
for x in range(0, W):
for y in range(0, H):
cy, cx = min(centers, key=lambda center: distance(center, (y, x)))
canvas[y, x] = canvas[cy, cx]
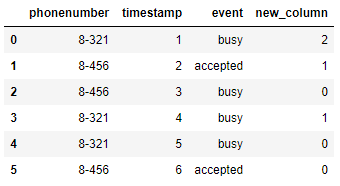
df['new_column'] = df.groupby(['phonenumber', 'event']).cumcount(ascending=False)