

from itertools import starmap
items = [
(161, 0, 'the-north-face', 25, 110),
(164, 1, 'ralf-Lauren', 87, 170),
(165, 2, 'the-north-face', 10, 75)
]
template = 'название: {2}, состояние: {3}, цена: {4}, продать: /sell_{1}'
message = '\n'.join(starmap(template.format, items))import cv2
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
if ret: # <<<<< этот параметр вам не просто так выдают
cv2.imshow("camera", img)
if cv2.waitKey(10) & 0xFF == 27: # <<<<< 0xFF
break
cap.release()
cv2.destroyAllWindows()text = 'ROMAlaPARIGIvendita'
from itertools import groupby
from string import ascii_lowercase
# Вариант #1
[''.join(group) for _, group in groupby(text, key=set(ascii_lowercase).issuperset)]
# Вариант #2
[''.join(group) for _, group in groupby(text, key=lambda c: c > 'Z')]with open('input.csv', 'r') as fi, open('output.csv', 'w') as fo:
print(*fi.readlines()[:-4], file=fo, sep='')import pandas a pd
pd.read_csv(..., skipfooter=4).to_csv(...)def salary(month, start_salary=5000, complex_percent=3.0):
return start_salary * pow(1 + complex_percent / 100, month - 1)
total = sum(print(f'{salary:.2f}') or salary for salary in map(salary, range(1, 12 + 1)))
print(f'Я заработал {total:.2f}')def criterion(number, denominators=[7, 9, 13], parity_mask=[1, 1, 0, 0, 0]):
if all(number % denominator != 0 for denominator in denominators):
if [int(digit) % 2 for digit in str(number)] == parity_mask:
return True
return False
numbers = list(filter(criterion, range(57888, 74555 + 1)))
print(len(numbers), max(numbers) - min(numbers))import cv2 # pip install opencv-python
import numpy as np # pip install numpy
import random
from collections import Counter, defaultdict
from functools import cmp_to_key
from itertools import combinations, permutations
from skimage.util import view_as_windows # pip install scikit-image
from PIL import Image # pip install pillow
h = w = 3 # будем использовать rolling window 3x3 (подобие свёртки)
n_channels = 3 # цветовые каналы изображения
n_samples = -1 # константа для более наглядного использования в .reshape()
active_pixels_in_3x3_cross = 5 # 5 из 9 пикселей образую крест ('+')
# Читаем картинку из файла
image = cv2.imread('5fc2a4fbb4bbd344880635.png', cv2.IMREAD_COLOR)
# Разбиваем изображение на блоки H x W @ CHANNELS и удаляем углы, чтобы получился крест из 5 пикселей
# Вместо view_as_windows() можно использовать np.lib.stride_tricks.as_strided(), но там очень сложно:
# tiles = np.lib.stride_tricks.as_strided(image, shape=(498, 498, 3, 3, 3), strides=(1500, 3, 1500, 3, 1))
tiles = view_as_windows(image, (h, w, n_channels)) # shape = (498, 498, 1, 3, 3, 3)
tiles = tiles.reshape(n_samples, h * w, n_channels) # shape = (248004, 9, 3)
tiles = tiles[:, (1, 3, 4, 5, 7), :] # shape = (248004, 5, 3)
# Нас интересуют только пересечения линий (полные кресты, где все 5 пикселей не чёрные)
mask = tiles.any(axis=-1).sum(axis=-1) == active_pixels_in_3x3_cross
crossovers = tiles[mask] # shape = (12, 5, 3)
# Собираем статистику
stats = defaultdict(Counter)
# Перебираем все пересечения цветных линий
for crossover in crossovers:
# Подсчитываем количество пикселей разных цветов, в сумме 5
counter = Counter(map(tuple, crossover))
# Добавляем в статистику
stats[frozenset(counter)] += counter
# Все встречающиеся цвета
all_colors = list({color for colors in stats for color in colors})
# Специально перемешаем, чтобы проверить устойчивость сортировки
random.shuffle(all_colors)
# Функция сравнения двух цветов
def cmp(color1, color2):
colors = frozenset({color1, color2})
if colors in stats: # явное лучше, чем неявное
num_pixels_of_color1 = stats[colors][color1]
num_pixels_of_color2 = stats[colors][color2]
return num_pixels_of_color1 - num_pixels_of_color2
else: # пара цветов не пересекается явным образом
return 0 # это может быть проблемой при сортировке
# Плохой алгоритм сортировки брутфорсом, но работает устойчиво
def sorted_colors():
for colors in permutations(all_colors, len(all_colors)):
for color1, color2 in combinations(colors, 2):
if cmp(color1, color2) > 0:
break
else: # обратите внимание на конструкцию for..else
return colors
# z_index = cmp_to_key(cmp)
# Рисуем отсортированную плашку цветов
Image.fromarray(
np.hstack(
# [np.full((64, 64, n_channels), color, np.uint8) for color in sorted(all_colors, key=z_index)]
[np.full((64, 64, n_channels), color, np.uint8) for color in sorted_colors()]
)[..., ::-1] # BGR -> RGB
)
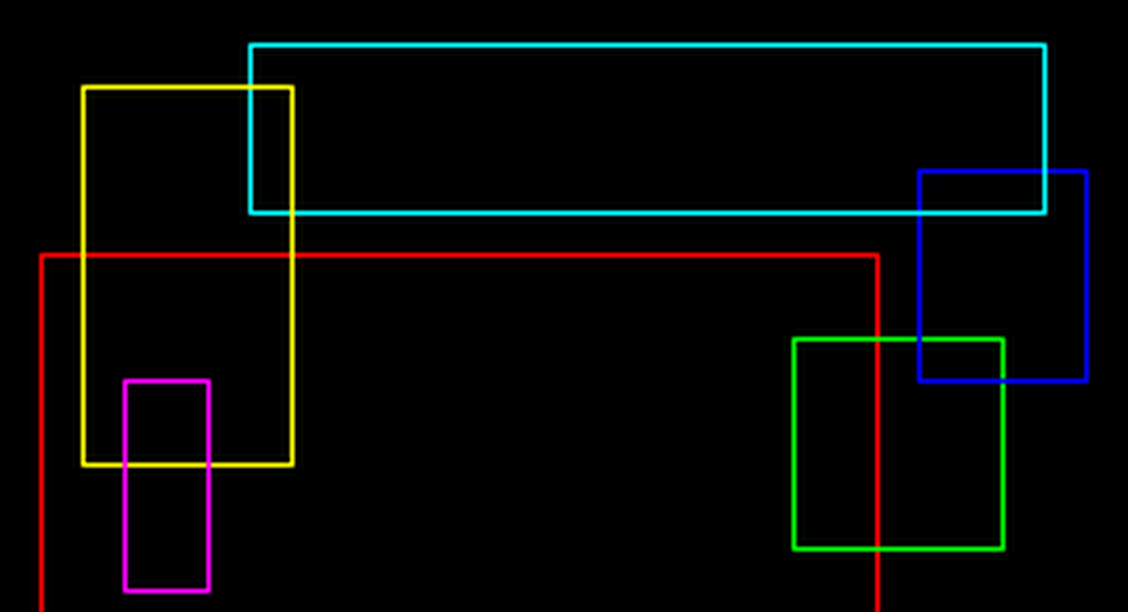
mask = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (0, 255, 255), (255, 255, 0)]
src = {
(0, 0, 255): ((0, 0, 5), (0, 0, 5), (0, 0, 23), (0, 0, 23)),
(255, 0, 0): ((0, 0, 10), (0, 0, 10), (0, 0, 21), (0, 0, 21)),
(0, 255, 0): ((0, 0, 15), (0, 0, 15), (0, 0, 21), (0, 0, 21)),
(255, 255, 0): ((0, 0, 20), (0, 0, 20), (0, 0, 21), (0, 0, 21)),
(0, 255, 255): ((0, 0, 24), (0, 0, 24), (0, 0, 21), (0, 0, 21))
}
dst = {key:src[key] for key in mask}
# Или так:
dst = dict(zip(mask, map(src.get, mask)))word1 = 'aabc'
word2 = 'aabacdff'
if any(word2.count(letter) < word1.count(letter) for letter in set(word1)):
option = 'нельзя'
else:
option = 'можно'
print(f'Первое слово {option} составить из букв второго')from collections import Counter
counter = Counter(word2)
counter.subtract(word1)
option = ('можно', 'нельзя')[bool(-counter)]
print(f'Первое слово {option} составить из букв второго')