def cprint(text):
class colored():
def __getattribute__(self, color):
print(f'text={text}, color={color}')
return colored()
cprint('test').greenmatrix = [[1, 2, 3], [4, 5, 6]]
for row in matrix:
for item in row:
print(item, end=' ')
print()for row in matrix:
print(*row)def decode(text, xkeys, ykeys):
return ''.join(text[4*(y-1)+(x-1)] for y in ykeys for x in xkeys)
print decode(u'ТЮАЕООГМРЛИПОЬСВ', (4,1,3,2), (3,1,4,2))>>> text
'blah. ! blah (beeep?) heap :) :) :)'
>>> re.sub(':(?!\))|(?<!:)\)|[^\w\s:)]', '', text)
'blah blah beeep heap :) :) :)'>>> from functools import partial
>>> smile = ':)'
>>> regex = partial(re.sub, '[^\w\s]', '')
>>> smile.join(map(regex, text.split(smile)))
'blah blah beeep heap :) :) :)'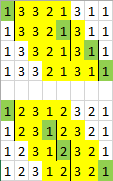
def solve(sequence):
def select(shift=0):
for start in range(4):
selection = sequence[start:][shift:5]
value = min(selection)
shift += selection.index(value)
yield value
return ''.join(select())
print(solve('13321311')) # 1111
print(solve('12312321')) # 1121
print(solve('33211213')) # 1113
print(solve('12345678')) # 1234
print(solve('21221132')) # 1112from itertools import chain, zip_longest
def mix(sequence, fltr=lambda e: e is not None):
return filter(fltr, chain(*zip_longest(sequence[1::2], sequence[0::2], fillvalue=None)))
print(''.join(mix('12345678'))) # => '21436587'
print(''.join(map(str, mix([1, 2, 3, 4, 5, 6, 7, 8, 9])))) # => '214365879'
print(list(mix([1, 2, 3, 4, 5, 6, 7, 8, 9]))) # => [2, 1, 4, 3, 6, 5, 8, 7, 9]from operator import itemgetter
def swap(sequence, keyfunc=itemgetter(1)):
min_value_index, min_value = min(enumerate(sequence), key=keyfunc)
max_value_index, max_value = max(enumerate(sequence), key=keyfunc)
sequence[min_value_index], sequence[max_value_index] = max_value, min_value
return sequence
print(swap([3, 4, 0, 7, 1, 9, 8, 6, 2, 5])) # => [3, 4, 9, 7, 1, 0, 8, 6, 2, 5]from collections import Counter, defaultdict
from itertools import imap
import re
codes = ['200', '3xx', '4xx', '5xx']
regex = re.compile('^.+?\[(?P<date>.+?) .+?\].+?(?P<code>\d+) \d+ ".+?" ".+?"$')
stats = defaultdict(Counter)
with open('access.log', 'r') as f:
for date, code in (match.groups() for match in imap(regex.match, f) if match):
stats[date].update([code if code == '200' else '{}xx'.format(code[0])])
for date, items in sorted(stats.iteritems()):
print date, ' '.join(str(items[code]) for code in codes)
# ---------- И ещё вариант ----------
from collections import Counter, defaultdict
from itertools import imap
from operator import methodcaller as mc
import re
codes = ['200', '3xx', '4xx', '5xx']
regex = re.compile('^.+?\[(?P<date>.+?) .+?\].+?(?P<code>\d+) \d+ ".+?" ".+?"$')
stats = defaultdict(Counter)
def fmt(code):
return code if code == '200' else '%sxx' % code[0],
with open('access.log', 'r') as f:
reduce(
lambda _, (date, code): stats[date].update(fmt(code)),
imap(mc('groups'), imap(regex.match, f)), None
)
for date, items in sorted(stats.iteritems()):
print date, ' '.join(imap(str, imap(items.__getitem__, codes)))
</code># -*- coding: utf-8 -*-
import re
from datetime import datetime, timedelta
months = u'января февраля марта апреля мая июня июля августа сентября октября ноября декабря'.split()
regexp = u'(?:(?P<yesterday>Вчера)|(?P<today>Сегодня)|(?P<day>\d{1,2})[ ](?P<month>[а-я]+))[ ](?P<hour>\d{2}):(?P<minute>\d{2})'
def postdate(text, posted=None):
if posted is None:
posted = datetime.now()
match = re.match(regexp, text, flags=re.U)
if match:
if match.group('today'):
pass
elif match.group('yesterday'):
posted -= timedelta(days=1)
else:
posted = posted.replace(
month = months.index(match.group('month')) + 1,
day = int(match.group('day'))
)
posted = posted.replace(
hour = int(match.group('hour')),
minute = int(match.group('minute')),
second = 0
)
return datetime.strftime(posted, "%d/%m/%Y %H:%M:%S")
print postdate(u'9 июля 11:41')
print postdate(u'Вчера 23:13')
print postdate(u'Сегодня 09:43')09/07/2015 11:41:00
06/08/2015 23:13:00
07/08/2015 09:43:00//*[@id="item"]//div[@class="item-views"]|/span
difflib.SequenceMatcher.find_longest_match()>>> from difflib import SequenceMatcher as SM
>>> s1 = 'A roza upala na lapu Azora'
>>> s2 = 'Dai, Djim, na s4astie lapu mne'
>>> sm = SM(lambda c: c in set(' ,'), s1, s2)
>>> m = sm.find_longest_match(0, len(s1), 0, len(s2))
>>> s1[m.a:m.b]
' lapu '>>> from itertools import islice
>>> s = islice(xrange(100), 27, 40, 3)
>>> s
<itertools.islice object at 0x02618060>
>>> list(s)
[27, 30, 33, 36, 39]