

import moviepy.editor as moviepy
clip = moviepy.VideoFileClip("myvideo.avi")
clip.write_videofile("myvideo.mp4")from more_itertools import divide
for n in range(2, 7):
print(f'n: {n} - {[list(x) for x in divide(n=n, iterable=[1, 2, 2, 3, 4, 3])]}\n')n: 2 - [[1, 2, 2], [3, 4, 3]]
n: 3 - [[1, 2], [2, 3], [4, 3]]
n: 4 - [[1, 2], [2, 3], [4], [3]]
n: 5 - [[1, 2], [2], [3], [4], [3]]
n: 6 - [[1], [2], [2], [3], [4], [3]]
Process finished with exit code 0import math
print(math.__file__)
pip install selenium-wirefrom seleniumwire import webdriver
options = {
'proxy': {
'http': 'http://username:password@host:port',
'https': 'https://username:password@host:port',
'no_proxy': 'localhost,127.0.0.1,dev_server:8080'
}
}
driver = webdriver.Firefox(seleniumwire_options=options)возможно ли сделать такое в принципе
и насколько это тяжело с технической точки зрения
на каком языке лучше написать подобную программу?
In [42]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [43]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [44]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])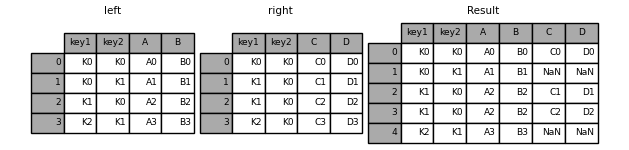
import pandas as pd
key = 'key'
left = pd.DataFrame({key: ['1', '2', '3', '4']})
right = pd.DataFrame({key: ['5', '4', '3', '2']})
df = pd.merge(left, right, on=key, how="outer", indicator=True)
print('Merged')
print(df)
df = df[df['_merge'] == 'left_only']
print('Result')
print(df)Merged
key _merge
0 1 left_only
1 2 both
2 3 both
3 4 both
4 5 right_only
Result
key _merge
0 1 left_onlyHm = ['Рис', 'Молоко', 'Помидоры', 'Лобстеры', 'Говядина', 'Пицца', 'Соус']
def Delete_List(x):
olditem = x[0]
del x[0]
print('Я купил', olditem)
print('Мой список выглядит так...', Hm, '\nБееее...ненавижу лобстеров, нужно вычеркнуть.')
del Hm[3]
while Hm:
print('Теперь мой список выглядит так: ', Hm)
Delete_List(Hm)Мой список выглядит так... ['Рис', 'Молоко', 'Помидоры', 'Лобстеры', 'Говядина', 'Пицца', 'Соус']
Бееее...ненавижу лобстеров, нужно вычеркнуть.
Теперь мой список выглядит так: ['Рис', 'Молоко', 'Помидоры', 'Говядина', 'Пицца', 'Соус']
Я купил Рис
Теперь мой список выглядит так: ['Молоко', 'Помидоры', 'Говядина', 'Пицца', 'Соус']
Я купил Молоко
Теперь мой список выглядит так: ['Помидоры', 'Говядина', 'Пицца', 'Соус']
Я купил Помидоры
Теперь мой список выглядит так: ['Говядина', 'Пицца', 'Соус']
Я купил Говядина
Теперь мой список выглядит так: ['Пицца', 'Соус']
Я купил Пицца
Теперь мой список выглядит так: ['Соус']
Я купил Соус
Process finished with exit code 0Такой вариант возможен?
Или же можно ли использовать python и javascript?
writer = pd.ExcelWriter(f'{os.path.join(graphs_dir, f"{i}.xlsx")}', engine='openpyxl', mode='a')def append_df_to_excel(filename, df, sheet_name='Sheet1', startrow=None,
truncate_sheet=False,
**to_excel_kwargs):
"""
Append a DataFrame [df] to existing Excel file [filename]
into [sheet_name] Sheet.
If [filename] doesn't exist, then this function will create it.
Parameters:
filename : File path or existing ExcelWriter
(Example: '/path/to/file.xlsx')
df : dataframe to save to workbook
sheet_name : Name of sheet which will contain DataFrame.
(default: 'Sheet1')
startrow : upper left cell row to dump data frame.
Per default (startrow=None) calculate the last row
in the existing DF and write to the next row...
truncate_sheet : truncate (remove and recreate) [sheet_name]
before writing DataFrame to Excel file
to_excel_kwargs : arguments which will be passed to `DataFrame.to_excel()`
[can be dictionary]
Returns: None
"""
from openpyxl import load_workbook
import pandas as pd
# ignore [engine] parameter if it was passed
if 'engine' in to_excel_kwargs:
to_excel_kwargs.pop('engine')
writer = pd.ExcelWriter(filename, engine='openpyxl')
# Python 2.x: define [FileNotFoundError] exception if it doesn't exist
try:
FileNotFoundError
except NameError:
FileNotFoundError = IOError
try:
# try to open an existing workbook
writer.book = load_workbook(filename)
# get the last row in the existing Excel sheet
# if it was not specified explicitly
if startrow is None and sheet_name in writer.book.sheetnames:
startrow = writer.book[sheet_name].max_row
# truncate sheet
if truncate_sheet and sheet_name in writer.book.sheetnames:
# index of [sheet_name] sheet
idx = writer.book.sheetnames.index(sheet_name)
# remove [sheet_name]
writer.book.remove(writer.book.worksheets[idx])
# create an empty sheet [sheet_name] using old index
writer.book.create_sheet(sheet_name, idx)
# copy existing sheets
writer.sheets = {ws.title:ws for ws in writer.book.worksheets}
except FileNotFoundError:
# file does not exist yet, we will create it
pass
if startrow is None:
startrow = 0
# write out the new sheet
df.to_excel(writer, sheet_name, startrow=startrow, **to_excel_kwargs)
# save the workbook
writer.save()
import ipaddress
for ip in ipaddress.IPv4Network('0.0.0.0/0'):
print(f'{ip}'){
"response": {
"GeoObjectCollection": {
"metaDataProperty": {
"GeocoderResponseMetaData": {
"request": "Москва,Тверская 6",
"results": "10",
"found": "1"
}
},
"featureMember": [
{
"GeoObject": {
"metaDataProperty": {
"GeocoderMetaData": {
"precision": "exact",
"text": "Россия, Москва, Тверская улица, 6с1",
"kind": "house",
"Address": {
"country_code": "RU",
"formatted": "Россия, Москва, Тверская улица, 6с1",
"postal_code": "125009",
"Components": [
{
"kind": "country",
"name": "Россия"
},
{
"kind": "province",
"name": "Центральный федеральный округ"
},
{
"kind": "province",
"name": "Москва"
},
{
"kind": "locality",
"name": "Москва"
},
{
"kind": "street",
"name": "Тверская улица"
},
{
"kind": "house",
"name": "6с1"
}
]
},
"AddressDetails": {
"Country": {
"AddressLine": "Россия, Москва, Тверская улица, 6с1",
"CountryNameCode": "RU",
"CountryName": "Россия",
"AdministrativeArea": {
"AdministrativeAreaName": "Москва",
"Locality": {
"LocalityName": "Москва",
"Thoroughfare": {
"ThoroughfareName": "Тверская улица",
"Premise": {
"PremiseNumber": "6с1",
"PostalCode": {
"PostalCodeNumber": "125009"
}
}
}
}
}
}
}
}
},
"name": "Тверская улица, 6с1",
"description": "Москва, Россия",
"boundedBy": {
"Envelope": {
"lowerCorner": "37.607242 55.757926",
"upperCorner": "37.615452 55.762556"
}
},
"Point": {
"pos": "37.611347 55.760241"
}
}
}
]
}
}
}{
"response": {
"GeoObjectCollection": {
"metaDataProperty": {
"GeocoderResponseMetaData": {
"request": "Киевская обл. , г. Киев, ул. Крещатик, дом 50, кв. 8",
"results": "10",
"found": "2"
}
},
"featureMember": [
{
"GeoObject": {
"metaDataProperty": {
"GeocoderMetaData": {
"precision": "exact",
"text": "Украина, Киев, улица Крещатик, 50",
"kind": "house",
"Address": {
"country_code": "UA",
"formatted": "Украина, Киев, улица Крещатик, 50",
"Components": [
{
"kind": "country",
"name": "Украина"
},
{
"kind": "province",
"name": "Киев"
},
{
"kind": "locality",
"name": "Киев"
},
{
"kind": "street",
"name": "улица Крещатик"
},
{
"kind": "house",
"name": "50"
}
]
},
"AddressDetails": {
"Country": {
"AddressLine": "Украина, Киев, улица Крещатик, 50",
"CountryNameCode": "UA",
"CountryName": "Украина",
"AdministrativeArea": {
"AdministrativeAreaName": "Киев",
"Locality": {
"LocalityName": "Киев",
"Thoroughfare": {
"ThoroughfareName": "улица Крещатик",
"Premise": {
"PremiseNumber": "50"
}
}
}
}
}
}
}
},
"name": "улица Крещатик, 50",
"description": "Киев, Украина",
"boundedBy": {
"Envelope": {
"lowerCorner": "30.516022 50.440632",
"upperCorner": "30.524232 50.445875"
}
},
"Point": {
"pos": "30.520127 50.443254"
}
}
},
{
"GeoObject": {
"metaDataProperty": {
"GeocoderMetaData": {
"precision": "other",
"text": "Украина, Киевская область",
"kind": "province",
"Address": {
"country_code": "UA",
"formatted": "Украина, Киевская область",
"Components": [
{
"kind": "country",
"name": "Украина"
},
{
"kind": "province",
"name": "Киевская область"
}
]
},
"AddressDetails": {
"Country": {
"AddressLine": "Украина, Киевская область",
"CountryNameCode": "UA",
"CountryName": "Украина",
"AdministrativeArea": {
"AdministrativeAreaName": "Киевская область"
}
}
}
}
},
"name": "Киевская область",
"description": "Украина",
"boundedBy": {
"Envelope": {
"lowerCorner": "29.266411 49.179114",
"upperCorner": "32.161466 51.554013"
}
},
"Point": {
"pos": "30.456149 50.29807"
}
}
}
]
}
}
}import numpy as np
def permgrid(m, n):
inds = np.indices((m,) * n, dtype='float')
return inds.reshape(n, -1).T
# Создаем матрицу перестановок
a = permgrid(10, 4)
# Перемножаем матрицу
a *= 0.001
def task(coef):
ad = float(coef[0] + coef[1] * coef[2] - coef[3])
if coef[0] != 0:
ad = ad / coef[0]
else:
ad = ad / 100
return ad
# Применяем функцию, итерируясь по строкам матрицы
task_result = np.apply_along_axis(task, 1, a)
# Вектор преобразуем из строки в столбец
task_result = np.reshape(task_result, (-1, 1))
# Присоединяем столбец к исходной матрице
a = np.concatenate((a, task_result), axis=1)import numpy as np
def trunc(values, decs=0):
stepper = 10.0 ** decs
return np.trunc(values * stepper) / stepper
a = np.random.sample((10, 5))
print(a)
a = trunc(a, 2)
print(a)[[0.80774294 0.49759797 0.12831778 0.0507127 0.93884821]
[0.40449397 0.66256411 0.68941394 0.9249191 0.24395077]
[0.04315995 0.18290855 0.5908672 0.2102119 0.81539927]
[0.35844866 0.5186572 0.29508712 0.57636076 0.64102832]
[0.94639274 0.09793527 0.73766807 0.80979653 0.84808608]
[0.46454466 0.58734548 0.63087822 0.10865253 0.82981857]
[0.8473419 0.23920123 0.3373125 0.4772781 0.35829208]
[0.03148842 0.70653864 0.85633527 0.72635685 0.47321859]
[0.76828975 0.08494009 0.45071368 0.79358861 0.6005338 ]
[0.3820037 0.02684243 0.1404288 0.04466791 0.32699522]]
[[0.8 0.49 0.12 0.05 0.93]
[0.4 0.66 0.68 0.92 0.24]
[0.04 0.18 0.59 0.21 0.81]
[0.35 0.51 0.29 0.57 0.64]
[0.94 0.09 0.73 0.8 0.84]
[0.46 0.58 0.63 0.1 0.82]
[0.84 0.23 0.33 0.47 0.35]
[0.03 0.7 0.85 0.72 0.47]
[0.76 0.08 0.45 0.79 0.6 ]
[0.38 0.02 0.14 0.04 0.32]]